JavaScript语言学习

JavaScript语言学习
月晕JAVASCRIPT 简介
javascript 最初被创建的原因是作在浏览器环境中使得浏览器的交互效果更加生动
javascript 这种编程语言写出来的程序称之为脚本 ,即是可以被直接写在网页的 HTML 中,在页面加载的时候自动执行。脚本被以纯文本的形式提供和执行。它们不需要特殊的准备或编译即可运行
发展到如今 JavaScript 不仅能在浏览器中执行,也可以在服务端执行,甚至可以在任意存在 Javascript 引擎的设置中执行
浏览器中嵌入了 JavaScript 引擎,有时也称作“JavaScript 虚拟机”。
比如:V8(javascript engine)、SpiderMonkey 等
引擎很复杂,但是基本原理很简单。
- 引擎(如果是浏览器,则引擎被嵌入在其中)读取(“解析”)脚本。
- 然后,引擎将脚本转化(“编译”)为机器语言。
- 然后,机器代码快速地执行。
引擎会对流程中的每个阶段都进行优化。它甚至可以在编译的脚本运行时监视它,分析流经该脚本的数据,并根据获得的信息进一步优化机器代码。
浏览器中的 JavaScript 能做什么?
现代的 JavaScript 是一种“安全的”编程语言。它不提供对内存或 CPU 的底层访问,因为它最初是为浏览器创建的,不需要这些功能。
JavaScript 的能力很大程度上取决于它运行的环境。例如,Node.js 支持允许 JavaScript 读取/写入任意文件,执行网络请求等的函数。
JavaScript 的上层语言
不同的人想要不同的功能。JavaScript 的语法也不能满足所有人的需求。
这是正常的,因为每个人的项目和需求都不一样。
因此,最近出现了许多新语言,这些语言在浏览器中执行之前,都会被 编译(转化)成 JavaScript。
现代化的工具使得编译速度非常快且透明,实际上允许开发者使用另一种语言编写代码并会将其“自动转换”为 JavaScript。
此类语言的示例有:
- CoffeeScript 是 JavaScript 的一种语法糖。它引入了更加简短的语法,使我们可以编写更清晰简洁的代码。
- TypeScript 专注于添加“严格的数据类型”以简化开发,以更好地支持复杂系统的开发。由微软开发。
- Flow 也添加了数据类型,但是以一种不同的方式。由 Facebook 开发。
- Dart 是一门独立的语言。它拥有自己的引擎,该引擎可以在非浏览器环境中运行(例如手机应用),它也可以被编译成 JavaScript。由 Google 开发。
- Brython 是一个 Python 到 JavaScript 的转译器,让我们可以在不使用 JavaScript 的情况下,以纯 Python 编写应用程序。
- Kotlin 是一个现代、简洁且安全的编程语言,编写出的应用程序可以在浏览器和 Node 环境中运行。
这样的语言还有很多。当然,即使我们在使用此类编译语言,我们也需要了解 JavaScript。因为了解 JavaScript 才能让我们真正明白我们在做什么。
基础知识
JavaScript 中的数据类型
原始数据类型:
Number
number 类型代表整数和浮点数
除了常规的数字,还包括所谓的“特殊数值(“special numeric values”)”也属于这种类型:Infinity、-Infinity 和 NaN
Infinity表示数学概念上的无穷大 ∞console.log(1/0) || console.log(Infinity)NaN代表一个计算错误它是一个不正确的或者一个未定义的数学操作所得到的结果1
console.log('not a number' / 2) //NaN
NaN是粘性的。任何对NaN的进一步数学运算都会返回NaN:1
2
3alert(NaN + 1) // NaN
alert(3 * NaN) // NaN
alert('not a number' / 2 - 1) // NaN
编写数字的更多方法:
1 | let billion = 1000000000 |
十进制、二进制、八进制
十六进制 数字在 JavaScript 中被广泛用于表示颜色,编码字符以及其他许多东西。所以自然地,有一种较短的写方法:0x,然后是数字。
1 | console.log(0xff) // 255 |
toString(base)
方法 num.toString(base) 返回在给定 base 进制数字系统中 num 的字符串表示形式。
1 | let num = 255 |
base 的范围可以从 2 到 36。默认情况下是 10。
舍入
Math.floor: 向下舍入Math.ceil: 向上舍入Math.round: 最近舍入Math.trunc: 移除小数点后的所有内容toFixed(n): 将数字舍入到小数点后n位,并以字符串形式返回结果。1
2
3
4
5
6let num = 12.34
alert(num.toFixed(1)) // "12.3"
num = 12.36
alert(num.toFixed(1)) // "12.4"
let num = 12.34
alert(num.toFixed(5)) // "12.34000",在结尾添加了 0,以达到小数点后五位我们可以使用一元加号或
Number()调用,将其转换为数字,例如+ num.toFixed(5)
不精确的计算:
在内部,数字是以 64 位格式IEEE-754,如果一个如果一个数字真的很大,则可能会溢出 64 位存储,变成一个特殊的数值 Infinity
1 | console.log(0.1 + 0.2 == 0.3) // false |
一个数字以其二进制的形式存储在内存中,一个 1 和 0 的序列。但是在十进制数字系统中看起来很简单的 0.1,0.2 这样的小数,实际上在二进制形式中是无限循环小数。
使用二进制数字系统无法 精确 存储 0.1 或 _0.2_,就像没有办法将三分之一存储为十进制小数一样。
IEEE-754 数字格式通过将数字舍入到最接近的可能数字来解决此问题。这些舍入规则通常不允许我们看到“极小的精度损失”,但是它确实存在。
最可靠的方法是借助方法 toFixed(n) 对结果进行舍入:
1 | let sum = 0.1 + 0.2 |
isNaN 和 isFinite
isNaN(value)将其参数转换为数字,然后测试它是否为NaN:1
2
3
4alert(isNaN(NaN)) // true
alert(isNaN('str')) // true
console.log(isNaN('123')) // false
alert(NaN === NaN) // falseisFinite(value)将其参数转换为数字,如果是常规数字而不是NaN/Infinity/-Infinity,则返回true1
2
3alert(isFinite('15')) // true
alert(isFinite('str')) // false,因为是一个特殊的值:NaN
alert(isFinite(Infinity)) // false,因为是一个特殊的值:Infinity
parseInt 和 pareseFloat:
使用加号 + 或 Number() 的数字转换是严格的。如果一个值不完全是一个数字,就会失败:
1 | alert(+'100px') // NaN |
但在现实生活中,我们经常会有带有单位的值,例如 CSS 中的 "100px" 或 "12pt"。
它们可以从字符串中“读取”数字,直到无法读取为止。如果发生 error,则返回收集到的数字。函数 parseInt 返回一个整数,而 parseFloat 返回一个浮点数:
1 | alert(parseInt('100px')) // 100 |
某些情况下,parseInt/parseFloat 会返回 NaN。当没有数字可读时会发生这种情况:
1 | alert(parseInt('a123')) // NaN,第一个符号停止了读取 |
parseInt() 函数具有可选的第二个参数。它指定了数字系统的基数,因此 parseInt 还可以解析十六进制数字、二进制数字等的字符串:
1 | alert(parseInt('0xff', 16)) // 255 |
其他数学函数:
Math.random():返回一个从 0 到 1 的随机数(不包括 1
Math.max(a, b, c...)和Math.min(a, b, c...): 从任意数量的参数中返回最大值和最小值。
Math.pow(n, power):返回 n 的给定(power)次幂。
Math.sqrt(100): 取根号
String
- 单引号:
let str = 'hello' - 双引号:
let str = "hello" - 反引号: let str = `hello`
字符串中的方法
常用
toUpperCase() || toLowerCase():改变大小写substring(start||0,end?length):获得子串slice(start,end):参数可以为负数,不破坏原来的串返回新的串replace(pattern:(string|regex,replacement:(string|function))):替换(pattern 是如果是 string,则只会替换第一项) –>replaceAllsplit(separator:(undefined||string||regex),limit?):分割字符形成数组,如果separator为undefined则会形成['str']includes(searchString,position?):boolean:查找是否包含indexof(serchValue,position?):index||-1:查找的字符串searchValue的第一次出现的索引,如果没有找到,则返回-1。lastIndexOf(serchValue,position?)
不常用
at()charAtcharCodeAt()match(regexp)startsWith(searchString,position?)endsWith(...)trim()
Boolean(逻辑类型)
布尔转换时
- 空值:即 0、” “、undefined、NaN、null 转换为
false - 其余为
true
注意 “0” 是 true 噢
逻辑运算
或运算(||)
传统的比如 if中使用 就不提了
1 | let res = value1 || value2 || value3 |
与运算(&&)
1 | console.log(1 && 0) // 0 |
非运算(!)
两个非运算 !! 有时候用来将某个值转化为布尔类型:
1 | alert(!!'non-empty string') // true |
值比较
严格相等
普通的相等性检查 == 存在一个问题,会先转换类型才会进行比较
1 | console.log(0 == false) //true |
严格相等运算符 === 在进行比较时不会做任何的类型转换。
1 | alert(0 === false) // false,因为被比较值的数据类型不同 |
null和undefined进行比较
1 | alert(null === undefined) // false |
?和??运算符
?运算符
1 | let result = condition ? value1 : value2 |
使用一系列问号 ? 运算符可以返回一个取决于多个条件的值
1 | let age = prompt('age?', 18) |
? 有时候能代替if但是可读性并不强 赋值的时可以考虑使用 ? 做逻辑判断的时候 if 更佳
空值合并运算符??
对待 null 和 undefined 的方式类似,所以当一个值既不是 null 也不是 undefined 时,我们将其称为“已定义的(defined)否则为未定义
a ?? b 的结果是:
- 如果
a是已定义的,则结果为a, - 如果
a不是已定义的,则结果为b。
1 | let result = a !== null && a !== undefined ? a : b |
1 | let firstName = null |
与||比较
它们之间重要的区别是:
||返回第一个 真 值。??返回第一个 已定义的 值。
换句话说,|| 无法区分 false、0、空字符串 "" 和 null/undefined。它们都一样 —— 假值(falsy values)。如果其中任何一个是 || 的第一个参数,那么我们将得到第二个参数作为结果。
不过在实际中,我们可能只想在变量的值为 null/undefined 时使用默认值。也就是说,当该值确实未知或未被设置时。
1 | let height = 0 |
Null
特殊的null值不属于任何一种类型构成了独立类型,仅代表无、空、值未知等状态
1 | let age = null |
Undefined
特殊值 undefined 和 null 一样自成类型。
如果一个变量已被声明,但未被赋值,那么它的值就是 undefined
1 | let age |
通常,使用 null 将一个“空”或者“未知”的值写入变量中,而 undefined 则保留作为未进行初始化的事物的默认初始值。
Symbol
“symbol” 值表示唯一的标识符,可以使用 Symbol() 来创建这种类型的值
1 | let id = Symbol('id') |
隐藏属性
symbol 允许我们创建对象的“隐藏”属性,代码的任何其他部分都不能意外访问或重写这些属性。
例如,如果我们使用的是属于第三方代码的 user 对象,我们想要给它们添加一些标识符。
我们可以给它们使用 symbol 键:
1 | let user = { |
我们的标识符和它们的标识符之间不会有冲突,因为 symbol 总是不同的,即使它们有相同的名字。
对象字面量中的 symbol
如果我们要在对象字面量 {...} 中使用 symbol,则需要使用方括号把它括起来。
1 | let id = Symbol('id') |
Symbol 会在 for in 中跳过
symbol 属性不参与 for..in 循环。
1 | let id = Symbol('id') |
Object.keys(user) 也会忽略它们。这是一般“隐藏符号属性”原则的一部分。如果另一个脚本或库遍历我们的对象,它不会意外地访问到符号属性。
相反,Object.assign 会同时复制字符串和 symbol 属性:
1 | let id = Symbol('id') |
全局 Symbol
要从注册表中读取(不存在则创建)symbol,请使用 Symbol.for(key)。
该调用会检查全局注册表,如果有一个描述为 key 的 symbol,则返回该 symbol,否则将创建一个新 symbol(Symbol(key)),并通过给定的 key 将其存储在注册表中。
1 | // 从全局注册表中读取 |
Symbol.keyFor
1 | // 通过 name 获取 symbol |
BigInt
BigInt 是一种特殊的数字类型,它提供了对任意长度整数的支持。
创建 bigint 的方式有两种:在一个整数字面量后面加 n 或者调用 BigInt 函数,该函数从字符串、数字等中生成 bigint。
1 | const bigint = 1234567890123456789012345678901234567890n |
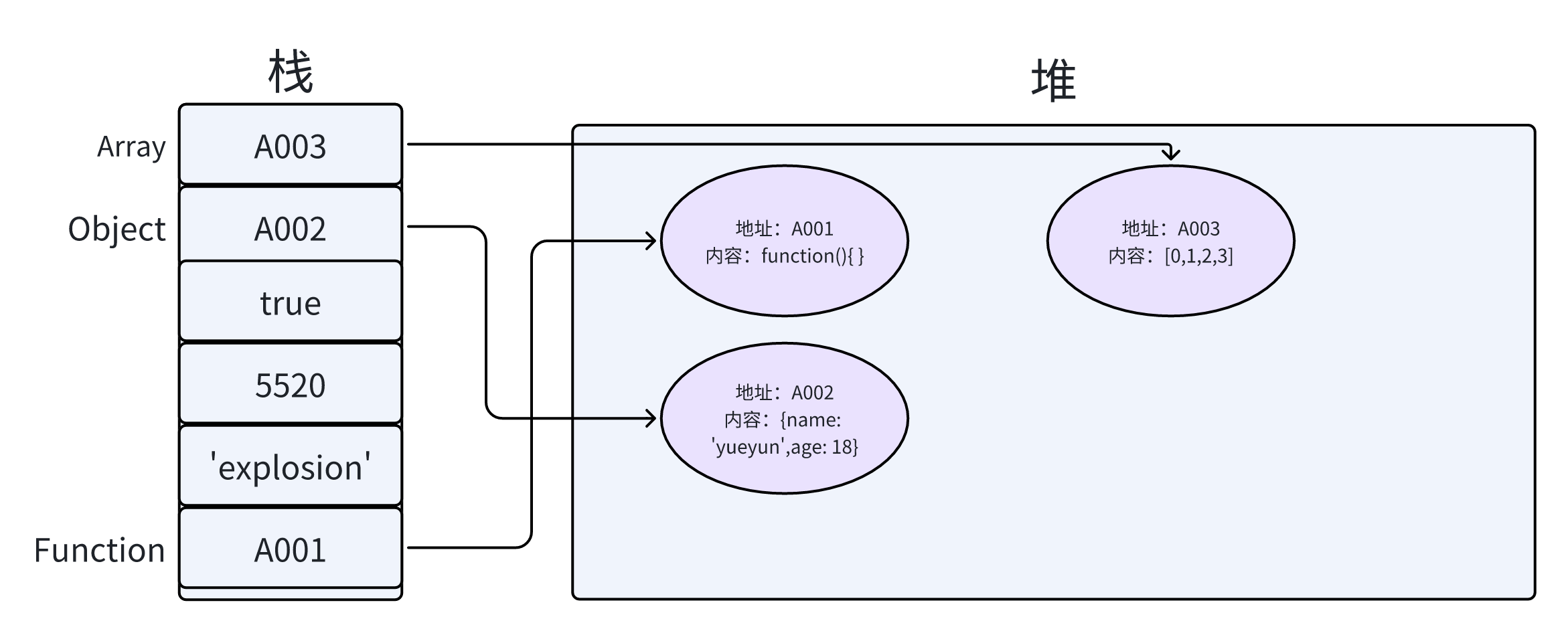
基本类型和引用类型
Javascript中栈和堆- 栈(stack):自动分配固定大小的内存空间,并由系统自动释放,栈数据结构遵从先进后出的原则
- 堆(heap):堆内存,动态分配内存,内存大小不固定,也不会自动释放,堆数据结构是一种无序的树状结构,满足
key-value键值对我们只用知道 key 名,就能通过 key 查找到对应的 value。比较经典的就是书架存书的例子,我们知道书名,就可以找到对应的书籍

引用类型的引用和复制
当一个对象变量被复制 —— 引用被复制,而该对象自身并没有被复制。
1
2
3let a = { name: '月晕', age: 18 }
let b = a
// 这里在堆内存中并没有新new 一份 {name: '月晕', age: 18},而只是把b的内容地址指向a的地址 指向堆内存中的同一份
非原始数据类型:
Object
Object 表示
1 | let user = new Object(); // “构造函数” 的语法 |
object 中 key 的计算属性
1 | let fruit = prompt('Which fruit to buy?', 'apple') |
Object 的引用和复制
对象与原始类型的根本区别之一是,对象是“通过引用”存储和复制的,而原始类型:字符串、数字、布尔值等 —— 总是“作为一个整体”复制。
当一个对象变量被复制 —— 引用被复制,而该对象自身并没有被复制。
1 | let user = { name: 'John' } |

克隆和合并,Object.assign
拷贝一个对象变量会又创建一个对相同对象的引用,复制一个对象,那该怎么做呢?
最先想到的就是遍历一份
1 | let user = { |
1 | // Object.assign(dest, src1, src2, src3,...) |
深层克隆:
到现在为止,我们都假设 user 的所有属性均为原始类型。但属性可以是对其他对象的引用。
当数组中存在对象抑或是对象中存在对象就要使用深拷贝
深拷贝可以使用 JSON 序列化(有优缺点)来做或者是自己手写一个深拷贝函数
lodash库中的.cloneDeep(obj)
使用 structuredClone() 去拷贝
Object 中的 this
this 即是函数的上下文,this 出现的值取决于它出现的上下文:函数、类或全局
函数写在对象中称之为对象的方法
方法中的this
通常, 对象方法需要访问对象中存储的信息才能完成其工作。
this 会指向一个对象:
- 以函数形式调用时、this 指向的是 widow(浏览器环境)/globalThis(nodejs 环境)
- 以方法的形式调用、this 指向的是调用方法的对象
1 | let user = { |
this 的值是在代码运行时计算出来的,它取决于代码上下文。
1 | let user = { name: 'John' } |
箭头函数没有自己的this
箭头函数有些特别:它们没有自己的 this。如果我们在这样的函数中引用 this,this 值取决于外部“正常的”函数。
1 | let user = { |
可选链?
可选链?. 是一种访问嵌套对象属性的安全的方式,即使中间属性不存在也不会出现错误
不存在属性问题:
如果我们有很多个 user 对象其中存储了我们的用户数据,我们大多数用户的地址都存储在 user.address 中,街道地址存储在 user.address.street 中,但有些用户没有提供这些信息。在这种情况下,当我们尝试获取 user.address.street,而该用户恰好没提供地址信息,我们则会收到一个错误:
1 | let user = {} // 一个没有 "address" 属性的 user 对象 |
javascritp 会把 user.address 识别为 undefined 尝试读取user.address.street 即是undefined.street自然是会失败并返回一个错误
在 Web 开发中,我们可以使用特殊的方法调用(例如 document.querySelector('.elem'))以对象的形式获取一个网页元素,如果没有这种对象,则返回 null。
1 | let html = document.querySelector('.elem').innerHTML |
同样,如果该元素不存在,则访问 null 的 .innerHTML 属性时会报错。在某些情况下,当元素的缺失是没问题的时候,我们希望避免出现这种错误,而是接受 html = null 作为结果。
首先我们想到的肯定是可以用if条件语句判断或者?运算符来解决
1 | let user = {} |
当层级多了之后显示会很臃肿而且不优雅 即引入了可选链?
1 | let user = {} // user 没有 address 属性 |
如果未声明变量
user,那么user?.anything会触发一个错误?.前的变量必须已声明(例如let/const/var user或作为一个函数参数)。可选链仅适用于已声明的变量。
当然也存在*?.() 和 ?.[]
Javascript 中的方法
原始类型的方法
string number bigInt boolean symbol null undefined
比如下面的这样
1 | let str = 'Hello' |
str.toUpperCase()中实际发生的情况
- 字符串
str是一个原始值。因此,在访问其属性时,会创建一个包含字符串字面值的特殊对象,并且具有可用的方法,例如toUpperCase()。 - 该方法运行并返回一个新的字符串(由
console.log显示)。 - 特殊对象被销毁,只留下原始值
str。
所以原始类型可以提供方法,但它们依然是轻量级的。
JavaScript 引擎高度优化了这个过程。它甚至可能跳过创建额外的对象。但是它仍然必须遵守规范,并且表现得好像它创建了一样。
数字有其自己的方法,例如,toFixed(n) 将数字舍入到给定的精度
数组中的方法
但很多时候我们发现还需要 有序集合,里面的元素都是按顺序排列的。例如,我们可能需要存储一些列表,比如用户、商品以及 HTML 元素等,这时一个特殊的数据结构数组(Array)就派上用场了,它能存储有序的集合。
从 JS 的数据类型本质上面来说 数组属于是一种特殊的对象
- 添加/删除元素
push(...items)—— 向尾端添加元素,pop()—— 从尾端提取一个元素,shift()—— 从首端提取一个元素,unshift(...items)—— 向首端添加元素,splice(pos, deleteCount, ...items)—— 从pos开始删除deleteCount个元素,并插入items。slice(start, end)—— 创建一个新数组,将从索引start到索引end(但不包括end)的元素复制进去。concat(...items)—— 返回一个新数组:复制当前数组的所有元素,并向其中添加items。如果items中的任意一项是一个数组,那么就取其元素。
- 搜索元素
indexOf/lastIndexOf(item, pos)—— 从索引pos开始搜索item,搜索到则返回该项的索引,否则返回-1。includes(value)—— 如果数组有value,则返回true,否则返回false。find/filter(func)—— 通过func过滤元素,返回使func返回true的第一个值/所有值。findIndex和find类似,但返回索引而不是值。
- 遍历元素
forEach(func)—— 对每个元素都调用func,不返回任何内容。
- 转换数组
map(func)—— 根据对每个元素调用func的结果创建一个新数组。sort(func)—— 对数组进行原位(in-place)排序,然后返回它。reverse()—— 原位(in-place)反转数组,然后返回它。split/join—— 将字符串转换为数组并返回。reduce/reduceRight(func, initial)—— 通过对每个元素调用func计算数组上的单个值,并在调用之间传递中间结果。
- 其他方法
Array.isArray(value)检查value是否是一个数组,如果是则返回true,否则返回false。
请注意,sort,reverse 和 splice 方法修改的是数组本身。
- 杂
- arr.some(fn)/arr.every(fn) 检查数组
- arr.fill(value, start, end) —— 从索引
start到end,用重复的value填充数组。 - arr.copyWithin(target, start, end) —— 将从位置
start到end的所有元素复制到 自身 的target位置(覆盖现有元素)。 - arr.flat(depth)/arr.flatMap(fn) 从多维数组创建一个新的扁平数组。
Iterable object(可迭代对象)
可迭代(Iterable) 对像是数组的泛化,即是对象可以在for of循环中使用
数组是可迭代的。但不仅仅是数组。很多其他内建对象也都是可迭代的。例如字符串也是可迭代的。
如果从技术上讲,对象不是数组,而是表示某物的集合(列表,集合),for..of 是一个能够遍历它的很好的语法,因此,让我们来看看如何使其发挥作用。
Symbol.iterator
比如现在有一个range对象代表了一个数字区间
1 | let range = { |
为了让range对象可以迭代我们需要手动为其添加一个Symbol.iterator方法
- 当
for..of循环启动时,它会调用这个方法(如果没找到,就会报错)。这个方法必须返回一个 迭代器(iterator) —— 一个有next方法的对象。 - 从此开始,
for..of仅适用于这个被返回的对象。 - 当
for..of循环希望取得下一个数值,它就调用这个对象的next()方法。 next()方法返回的结果的格式必须是{done: Boolean, value: any},当done=true时,表示循环结束,否则value是下一个值。
1 | const range = { |
无穷迭代器(iterator)
无穷迭代器也是可能的。例如,将
range设置为range.to = Infinity,这时range则成为了无穷迭代器。或者我们可以创建一个可迭代对象,它生成一个无穷伪随机数序列。也是可能的。
next没有什么限制,它可以返回越来越多的值,这是正常的。当然,迭代这种对象的
for..of循环将不会停止。但是我们可以通过使用break来停止它。
字符串迭代
1 | const chars = 'abcdef' |
显示调用迭代器
为了更深层地了解底层知识,让我们来看看如何显式地使用迭代器。
我们将会采用与 for..of 完全相同的方式遍历字符串,但使用的是直接调用。这段代码创建了一个字符串迭代器,并“手动”从中获取值。
1 | let str = 'yueyun' |
很少需要我们这样做,但是比 for..of 给了我们更多的控制权。例如,我们可以拆分迭代过程:迭代一部分,然后停止,做一些其他处理,然后再恢复迭代。
可迭代(iterable)和类数组(array-like)
- Iterable 如上所述,是实现了
Symbol.iterator方法的对象。 - Array-like 是有索引和
length属性的对象,所以它们看起来很像数组。
Array.from
有一个全局方法 Array.from 可以接受一个可迭代或类数组的值,并从中获取一个“真正的”数组。然后我们就可以对其调用数组方法了。
1 | let arrayLike = { |
1 | // 接受上面的range 生成数组 |
可选的第二个参数 mapFn 可以是一个函数,该函数会在对象中的元素被添加到数组前,被应用于每个元素,此外 thisArg 允许我们为该函数设置 this。
1 | // 求每个数的平方 |
Map 和 Set(映射和集合)
Map
Map是一个带键的数据项集合.就跟Object一样,区别就是Map的key允许是任意类型
Map 的方法和属性如下
new Map()—— 创建 map。map.set(key, value)—— 根据键存储值。map.get(key)—— 根据键来返回值,如果map中不存在对应的key,则返回undefined。map.has(key)—— 如果key存在则返回true,否则返回false。map.delete(key)—— 删除指定键的值。map.clear()—— 清空 map。map.size—— 返回当前元素个数。
Map 可以使用对象来做键
2
3
4
5
6
// 存储每个用户的来访次数
let visitsCountMap = new Map()
// john 是 Map 中的键
visitsCountMap.set(john, 123)
console.log(visitsCountMap.get(john)) // 123使用对象作为键是
Map最值得注意和重要的功能之一。在Object中,我们则无法使用对象作为键。在Object中使用字符串作为键是可以的,但我们无法使用另一个Object作为Object中的键
map.set调用都会返回 map 本身 即我们可以进行链式调用
Map 迭代
如果要在Map里使用循环 可以使用下面的方法
map.keys()遍历并返回一个包含所有键的可迭代对象map.values()—— 遍历并返回一个包含所有值的可迭代对象,map.entries()—— 遍历并返回一个包含所有实体[key, value]的可迭代对象,for..of在默认情况下使用的就是这个。
1 | let recipeMap = new Map([ |
迭代的顺序与插入值的顺序相同。与普通的
Object不同,Map保留了此顺序。
Map中有内建的forEach
1 | // 对每个键值对 (key, value) 运行 forEach 函数 |
Map 和对象的转换
Object.entries:从对象创建 Map
1 | let obj = { |
Object.fromEntries:从 Map 创建对象
1 | let prices = Object.fromEntries([ |
当 Map 中含有对象作为 key 时 专成对象时的 key 会变成
'[object object]'
Set
Set 是一个特殊的类型集合 —— “值的集合”(没有键),它的每一个值只能出现一次。 它的主要方法如下:
new Set(iterable)—— 创建一个set,如果提供了一个iterable对象(通常是数组),将会从数组里面复制值到set中。set.add(value)—— 添加一个值,返回 set 本身set.delete(value)—— 删除值,如果value在这个方法调用的时候存在则返回true,否则返回false。set.has(value)—— 如果value在 set 中,返回true,否则返回false。set.clear()—— 清空 set。set.size—— 返回元素个数。
它的主要特点是,重复使用同一个值调用 set.add(value) 并不会发生什么改变。这就是 Set 里面的每一个值只出现一次的原因。
1 | let set = new Set() |
Set 迭代(iteration)
我们可以使用 for..of 或 forEach 来遍历 Set:
1 | let set = new Set(['oranges', 'apples', 'bananas']) |
WeakMap 和 WeakSet
在垃圾回收中 Javascript 引擎在值“可达”和“可使用”时会将其保存在内存中
1 | let yueyun = { name: 'yueyun', age: 18 } |
通常 当对象,数组之类的数据结构在内存中时,它们的子元素 如对象的属性,数组的元素都是认为可达的 例如,如果把一个对象放入到数组中,那么只要这个数组存在,那么这个对象也就存在,即使没有其他对该对象的引用。
1 | let yueyun = { name: 'yueyun', age: 18 } |
所以当我们使用对象作为 Map 的键的时 如果 Map 存在 那么对象就会一直存在占用内存不会被垃圾回收
WeakMap 在这方面有着根本上的不同。它不会阻止垃圾回收机制对作为键的对象(key object)的回收。
WeakMap
WeakMap 和 Map 的第一个不同点就是,WeakMap 的键必须是对象,不能是原始值:
1 | let weakMap = new WeakMap() |
现在,如果我们在 weakMap 中使用一个对象作为键,并且没有其他对这个对象的引用 —— 该对象将会被从内存(和 map)中自动清除。
1 | let yueyun = { name: 'yueyun' } |
与常规的map相比 如果yueyun仅仅是作为 WeakMap 的键而存在 —— 它将会被从 map(和内存)中自动删除。
WeakMap 不支持迭代以及 keys(),values() 和 entries() 方法。所以没有办法获取 WeakMap 的所有键或值。WeakMap 只有以下的方法:
weakMap.get(key)weakMap.set(key, value)weakMap.delete(key)weakMap.has(key)
WeakSet
WeakSet 的表现类似:
- 与
Set类似,但是我们只能向WeakSet添加对象(而不能是原始值)。 - 对象只有在其它某个(些)地方能被访问的时候,才能留在
WeakSet中。 - 跟
Set一样,WeakSet支持add,has和delete方法,但不支持size和keys(),并且不可迭代。
变“弱(weak)”的同时,它也可以作为额外的存储空间。但并非针对任意数据,而是针对“是/否”的事实。WeakSet 的元素可能代表着有关该对象的某些信息。
例如,我们可以将用户添加到 WeakSet 中,以追踪访问过我们网站的用户:
1 | let visitedSet = new WeakSet() |
解构赋值
JavaScript 中最常用的数据结构是Object和Array 解构赋值是一种特殊的语法 将数组或对象拆包到一系列的变量中
数组解构
1 | const [firstName, lastName] = 'yue yun'.split(' ') |
解构并没有破坏 只是方便简单的赋值
有想忽略的元素
1 | const [firstName, , title] = ['yueyun', 'megumi', 'korumi'] |
等号的右侧可以是任何可迭代的对象
1 | let [a, b, c] = 'abc' // ["a", "b", "c"] |
交换变量值的技巧
1 | let guest = 'yue' |
其余的 ...
通常,如果数组比左边的列表长,那么“其余”的数组项会被省略。如果我们还想收集其余的数组项 —— 我们可以使用三个点 "..." 来再加一个参数以获取其余数组项:
1 | const [name1, name2, ...rest] = [ |
我们也能使用...去快速浅拷贝或者赋值
1 | const oldArr = ['yueyun', 'meigumi', 'kurumi', 'explosion'] |
默认值
1 | const [name = 'yueyun', age = 18] = ['yueyun2'] |
对象解构
解构赋值同样适用于对象
1 | // 基本情况是 |
属性 options.title、options.width 和 options.height 值被赋给了对应的变量。变量的顺序并不重要
可以取别名映射 也可以默认赋值 也可以使用 … 去解构
1 | let options = { |
注意使用声明 (javascript 代码块)
嵌套解构
建议不要使用捏 会让简单的变得很烦
智能函数参数
有这样的场景 一个函数需要接受很多参数 而且大部分参数都是可选的
下面是很糟糕的写法
1 | function showMenu(title = 'Untitled', width = 200, height = 100, items = []) { |
在实际开发中,记忆如此多的参数的位置是一个很大的负担。通常集成开发环境(IDE)会尽力帮助我们,特别是当代码有良好的文档注释的时候,但是…… 另一个问题就是,在大部分的参数只需采用默认值的情况下,调用这个函数时会需要写大量的 undefined。
1 | // 在采用默认值就可以的位置设置 undefined |
这太难看了。而且,当我们处理更多参数的时候可读性会变得很差。
解构赋值可以解决这些问题。我们可以用一个对象来传递所有参数,而函数负责把这个对象解构成各个参数:
1 | // 我们传递一个对象给函数 |
我们也可以使用带有嵌套对象和冒号映射的更加复杂的解构:
1 | let options = { |
完整语法和解构赋值是一样的:
1 | function({ |
我们可以通过指定空对象 {} 为整个参数对象的默认值来解决这个问题:
1 | function showMenu({ title = 'Menu', width = 100, height = 200 } = {}) { |
JSON 方法 toJSON
javascript 的一些数据结构是属于独有的 当传输网络数据或者在日志输出的时候需要传输数据
JSON.stringify
JSON(JavaScript Object Notation)是表示值和对象的通用格式。在 RFC 4627 标准中有对其的描述。最初它是为 JavaScript 而创建的,但许多其他编程语言也有用于处理它的库。因此,当客户端使用 JavaScript 而服务器端是使用 Ruby/PHP/Java 等语言编写的时,使用 JSON 可以很容易地进行数据交换。
JavaScript 提供了如下方法:
JSON.stringify将对象转换成JSONJSON.parse将 JSON 转换成对象
1 | let student = { |
方法JSON.stingify(stduent)接受对象并将其转换成字符串
得到的JSON字符串是一个被称之为JSON 编码(JSON-encoded)或 序列化 或 字符串化 或 编组化的对象JSON.stringify 也可以应用于原始(primitive)数据类型。
JSON 支持的数据类型:
- Objects
{ ... } - Arrays
[ ... ] - Primitives:
- strings,
- numbers,
- boolean values
true/false, null
JSON 是语言无关的纯数据规范,因此一些特定于 JavaScript 的对象属性会被 JSON.stringify 跳过。即:
- 函数属性(方法)。
- Symbol 类型的键和值。
- 存储
undefined的属性。
支持嵌套对象转换 但是不能循环引用JSON.stringify的完整语法是let json = JSON.stringify(value,replacer, space)
value:要编码的值、replacer:要编码属性数组活映射函数、space:用于美化输出的空格数
1 | const room = { |
JSON.parse
要解码 JSON 字符串 需要使用JSON.parse方法let value = JSON.parse(str,reviver)
str:要解析的 JSON 字符串、reviver:可选的函数,将为每个(键,值)对调用此函数
1 | // 字符串化数组 |
总结
- JSON 是一种数据格式,具有自己的独立标准和大多数编程语言的库。
- JSON 支持 object,array,string,number,boolean 和 null。
- JavaScript 提供序列化(serialize)成 JSON 的方法 JSON.stringify 和解析 JSON 的方法 JSON.parse。
- 这两种方法都支持用于智能读/写的转换函数。
- 如果一个对象具有 toJSON,那么它会被 JSON.stringify 调用。
规范和调试
高级内容
函数
递归
在函数解决任务时 调用了自身就是所谓的递归
比如想在要完成一个函数pow(x, n)可以计算x的n次方 有两种解法
迭代思路 使用
for循环1
2
3
4
5
6
7function pow(x, n) {
let result = 1
for (let i = 0; i < n; i++) {
result *= x
}
return result
}递归思路:简化任务 调用自身
1
2
3
4
5
6
7function pow(x, n) {
if (n === 1) {
return x
} else {
return x * pow(x, n - 1)
}
}
当pow(x, n)被调用时 执行分为下面两个分支:
1 | if n==1 = x |
- 当
n===1时 叫做基础递归 因为会产生明显的结果 - 可以使用
x * pow(x, n - 1)表示pow(x, n)这就递归步骤将人物转化为更简单的行为和更简单的同类任务调用 (带有更小的n的pow运算)。接下来的步骤将其进一步简化,直到n达到1。
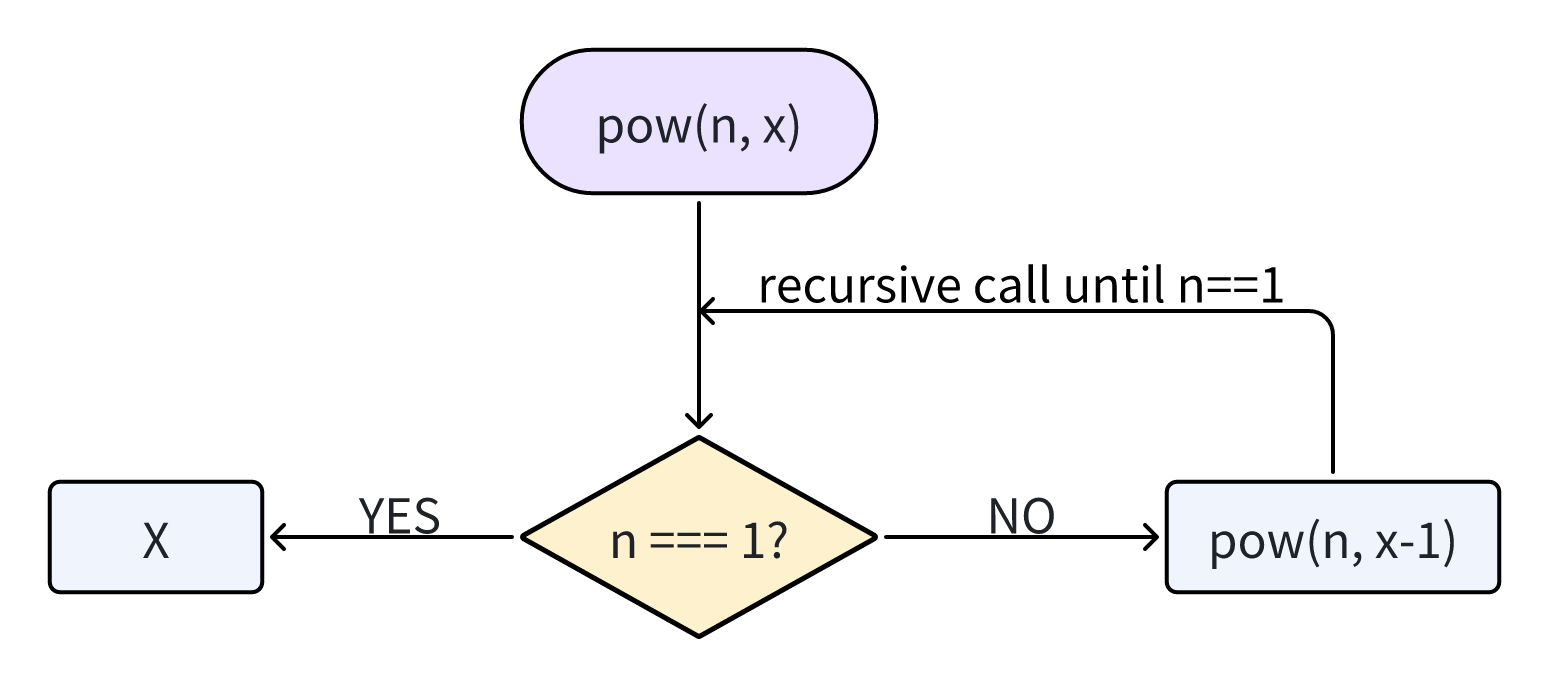
递归将函数调用简化成为一个更简单的函数调用 然后在将其简化为一个更加简单的函数 以此类推 直到结果变得显而易见
最大的嵌套调用次数(包括首次)被称为递归深度 在上面这个例子正好为 n
执行上下文和堆栈
递归调用的工作 函数底层的工作原理
有关正在运行的函数的执行过程的相关信息被存储在其执行上下文中
执行上下文是一个内部据结构 他包含有关函数执行时的详细细节:
- 当前控制流所在的位置 (作用域链):每个执行上下文都有一个与之相关联的作用域链。作用域链是一个对象列表,它定义了变量和函数的查找规则,决定了代码在哪些区域是有效的。当代码在一个执行上下文中查找变量时,如果在当前上下文的变量对象中找不到,它会沿着作用域链向上查找。
- 当前的变量:包含函数的参数、局部变量、函数声明、变量声明 在函数执行的初始阶段 函数所有的参数值、函数内部的函数声明以及变量声明都会被添加到变量对象中。
this的值:表示调用上下文,依赖于函数的调用方式 全局执行上下文 函数执行上下文(如何被调用)- 及内部的一些细节
一个函数调用仅具有一个与其关联的执行上下文
当一个函数进行嵌套调用的时候 将发生
- 当前函数被暂停
- 与它关联的执行上下文被一个叫做
执行上下文堆栈而特殊数据结构保存 - 执行嵌套调用
- 嵌套调用结束后 从堆栈中恢复之前的执行上下文 并从停止的位置恢复外部函数
比如现在来分析上面 pow(2,3) 这个例子 使用抽象的来表示一下执行流程
在调用
pow(2, 3)而开始,执行上下文(context)会储存变量:x = 2, n = 3执行流程在函数而第一行我们将其定义为Context: { x:2, n:3, at line 1 }call pow(2, 3)
当函数开始执行的时 进入第二条分支 变量相同但是位置改变了
**Context: { x:2, n:3, at line 5 }call pow(2, 3) **执行到计算
x * pow(x, n - 1)需要带入新的参数新的pow子调用pow(2,2)为了执行嵌套调用,JavaScript 会在 执行上下文堆栈 中记住当前的执行上下文。
这里我们调用相同的函数
pow,但这绝对没问题。所有函数的处理都是一样的:- 当前上下文被“记录”在堆栈的顶部。
- 为子调用创建新的上下文。
- 当子调用结束后 —— 前一个上下文被从堆栈中弹出,并继续执行。
下面是进入子调用
pow(2, 2)时的上下文堆栈:**
Context: { x:2, n:2, at line 5 }call pow(2, 2) **
**Context: { x:2, n:3, at line 5 }call pow(2, 3) **
当我们完成了子调用后 很容易恢复一个上下文 因为它既保留了变量 也保留了当时代码的确切位置执行
pow(2, 1)重复过程 现在的调用堆栈Context: { x:2, n:1, at line 5 }call pow(2, 1)**
Context: { x:2, n:2, at line 5 }call pow(2, 2) **
**Context: { x:2, n:3, at line 5 }call pow(2, 3) **出口 即使调用堆栈 出栈口
递归可以更加简单明了优雅的描述出一段代码的逻辑 虽然性能上可能不如循环但是在一些复杂的数据结构下面使用递归往往更好 (比如 树 链表等)
Rest 参数和 Spread 语法
简单来说就是
function sum (...args)
1 | cosnt arr2 = [1,2,3,4,5] |
变量作用域和闭包
JavaScript是非常面向对象和函数的语言 会有很大的自由度和写法 我们可以随时创建函数可以将函数作为参数传递 在任意不同的代码位置调用 可以访问外部的环境
代码块
如果在{ ... }内声明变量 那么这个变量并不会向外传递 只能在内部访问该代码块内可见
1 | let a = 10 |
在if, for, while 中 {...}中声明的变量也仅在内部可见
嵌套函数
如果一个函数在另外一个函数中创建的 被称为高级函数或者嵌套函数
1 | function sayHiBye(firstName, lastName) { |
词法环境
变量:
在 Javascript 中每个 运行的函数 代码块 { ... } 以及整个脚本都有一个被称为词法**环境(Lexical Enviroment)**的内部的关联对象
该词法环境对象由两部分组成:
- 环境记录(Enviroment Record) 一个存储所有局部变量作为其属性 (包括一些其他的信息 例如
this的值)的对象 - 对外部词法环境的引用 与外部代码相关联
一个变量只是**”环境记录”**这个特殊的内部对象的一个属性 获取或修改变量一味着获取或修改词法环境的一个属性 “获取或修改变量” 意味着 获取或修改词法环境的一个属性
比如下面的一个最简单的例子
1 | let phrase = 'hello' |
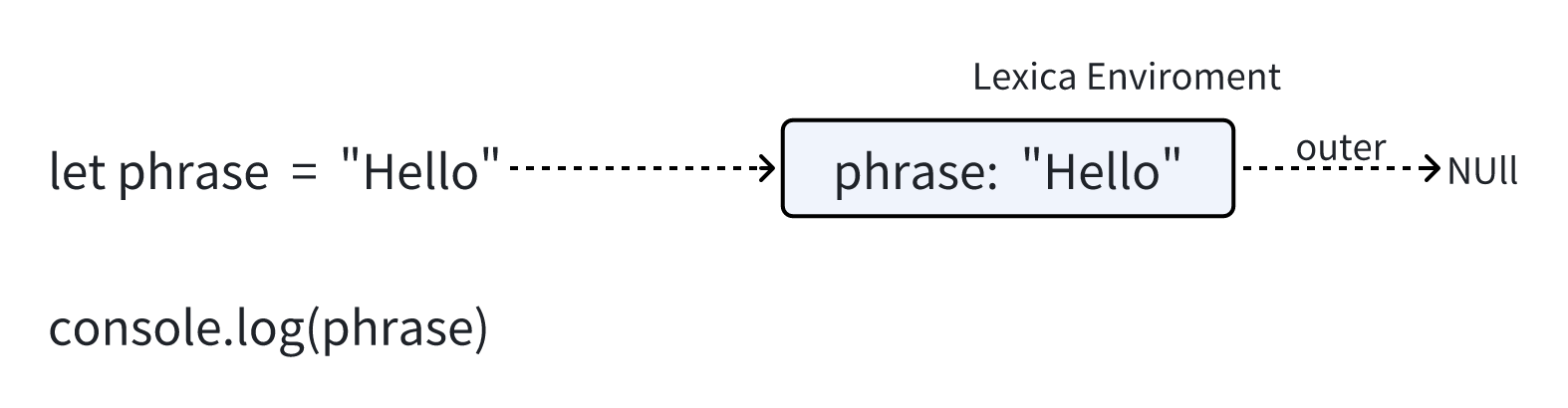
这个就是所谓的与整个脚本相关联的全局词法环境
在上面的过程中 矩形区域表示环境记录(变量存储) 箭头表示外部引用 全局词法环境没有外部引用 所以箭头指向了null
随着代码的开始继续的执行 词法环境发生了变化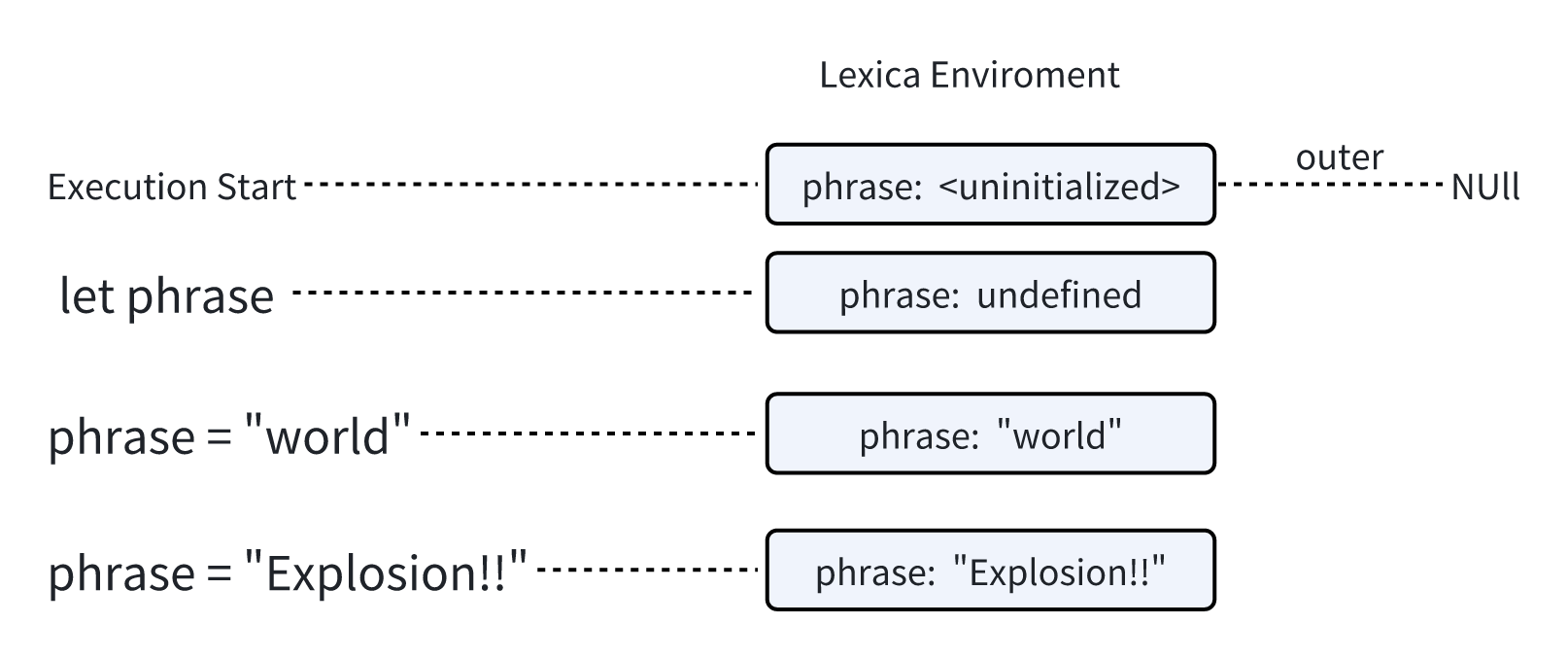
上面的图片中右侧演示了执行过程中词法环境的变化:
- 当脚本开始运行 词法环境先填充了所有声明的变量
在最初 它们处于未初始化的状态这是一种特殊的内部状态 这意味着引擎知道这个变量存在但是在 let 声明之前 不能引用它 几乎就跟不存在一样 let phrase定义出现 尚未被赋值 因此值是undefinedphrase被赋予了一个值phrase被修改
实际上执行的过程是
- 变量是特殊内部对象的属性 与当前正在执行的**(代码)块/函数/脚本** 有关
- 操作变量实际上是操作该对象的属性
词法环境是一个规范的对象 是存在于语言规范的理论层面 用于描述是如何工作的 我们无法在代码块中获取该对象并直接进行操作
函数声明:
一个函数其实就是一个值 就像变量一样
不同就在于 如果是函数声明的初始化会被立刻完成
当创建了一个词法环境时,函数会立即变成即用型函数( 并不像 let 那样到声明处才可以去使用)
例如 下面是添加一个函数时全局词法环境的初始状态
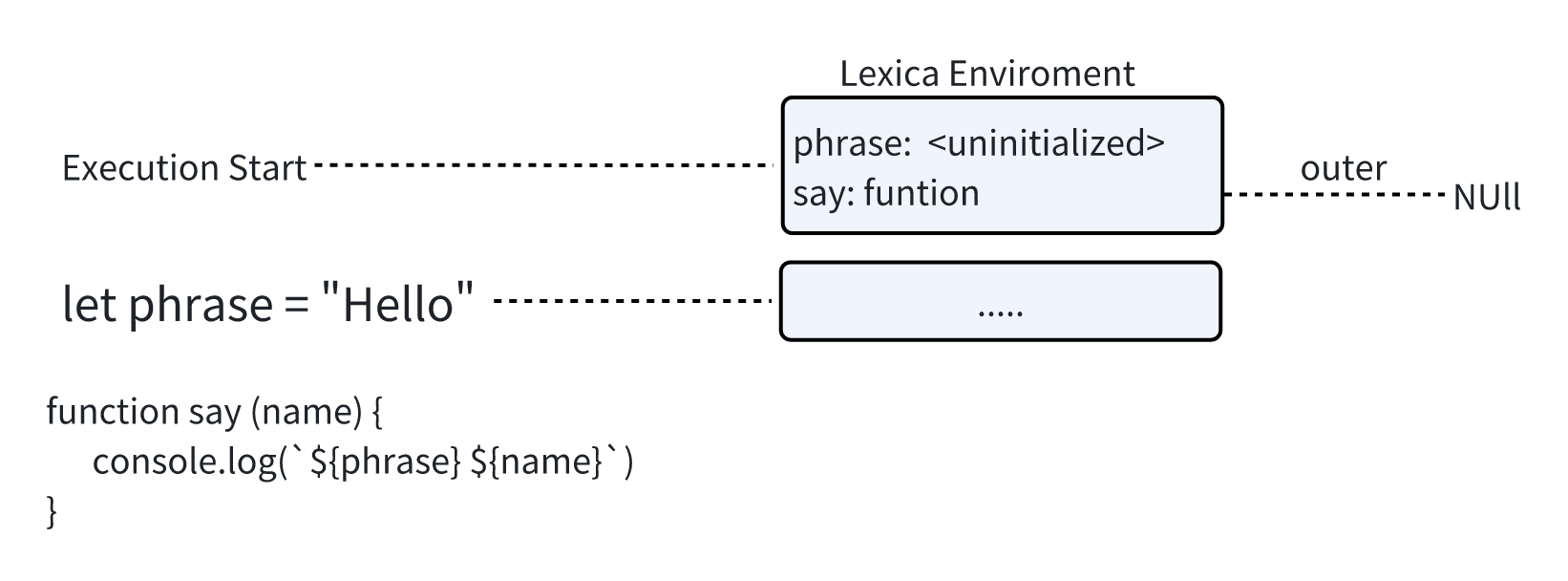
这种行为仅适用于函数声明 而不适用于匿名函数的声明 比如let sayHello = function () {...} 或者 let sayhello = () => {...}
内部和外部的词法环境
当一个函数运行时 在调用刚开始 会自动创建一个新的词法环境以存储这个调用的局部变量和参数 例如对于say("yueyun") 的执行流程如下
1 | let phrase = ' Hello ' |

在函数调用期间我们拥有两个词法环境 内部一个(用于函数调用) 和外部一个(全局):
- 内部词法环境与
say的当前执行相对应 它具有单独的属性:name函数的参数 调用的是say("yueyun")所以name的值为yueyun - 外部词法环境是全局词法环境 它具有
phrase变量和函数本身
内部词法环境引用了outer
当代码要访问一个变量时 —— 首先会搜索内部词法环境,然后搜索外部环境,然后搜索更外部的环境,以此类推,直到全局词法环境。
返回函数:
比如下面的例子
1 | function makeCounter() { |
在每次makeCounter()调用的开始,都会创建一个新的词法环境对象,以存储该makeCounter运行时的变量
因此,我们有两层嵌套的词法环境
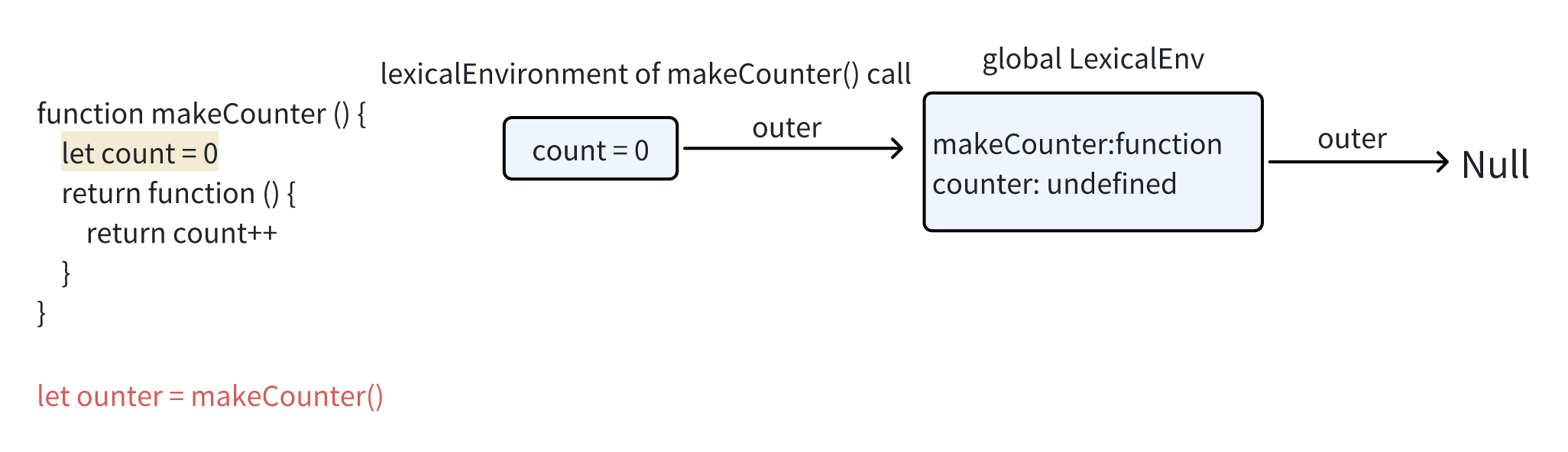
不一样的是 在执行 makeCounter()的过程中创建了一个仅占一行的嵌套函数 return count++ 我们并没有运行它 只是创建了这么一个函数
所有的函数在创建时都会记住它的词法环境 从技术上来说 所有的函数都有名为[[Environment]]的隐藏属性 该属性保存了对创建对象该函数的词法环境的应引用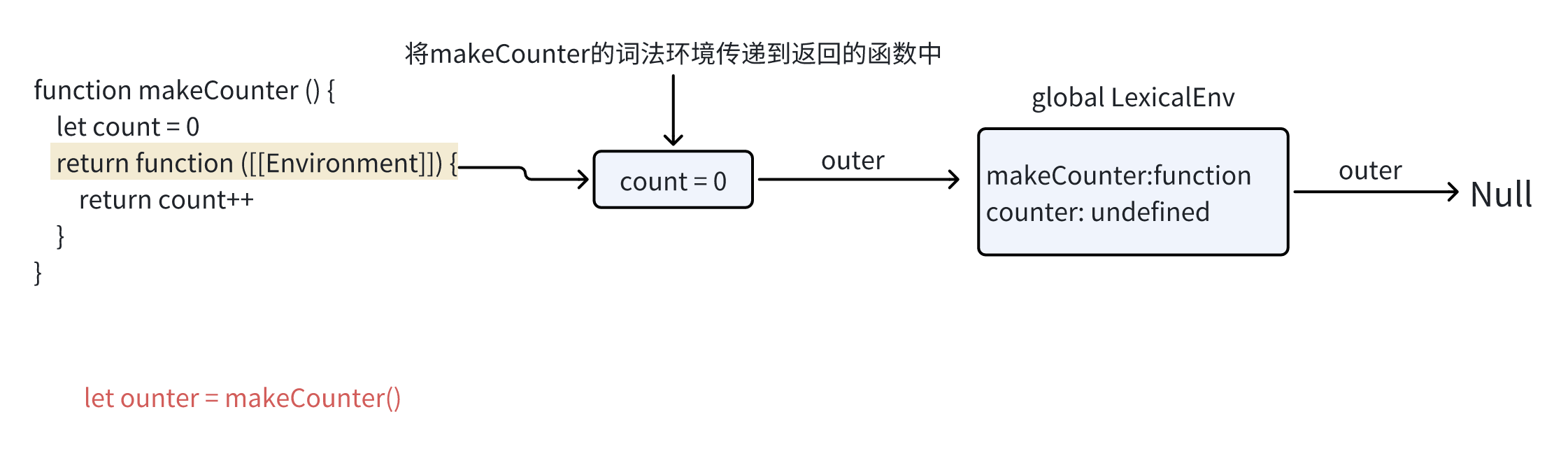
因此 counter.[[Env]] 有对 {count: 0}词法环境的引用 这就是函数记住它创建于何处的方式与调用无关 [[Environment]] 引用在函数创建时被设置并永久保存。
稍后调用counter()时,会自动创建一个新的词法环境 并且其外部词法环境引用获取于counter.[[Environment]]
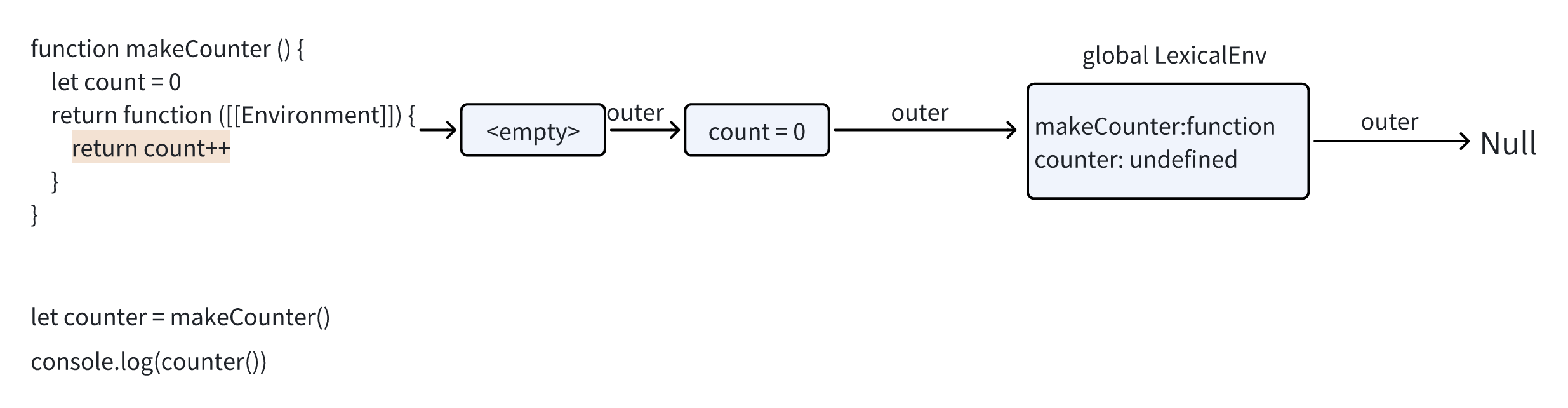
现在,当 counter() 中的代码查找 count 变量时,它首先搜索自己的词法环境(为空,因为那里没有局部变量),然后是外部 makeCounter() 的词法环境,并且在哪里找到就在哪里修改。
在变量所在的词法环境中更新变量
如果我们调用 counter() 多次,count 变量将在同一位置增加到 2,3 等。
闭包是一个编程术语 是指一个函数可以记住其他外部变量并可以访问这些变量 在某些编程语言中 会有不同的差异 但在Javascript中 所有的函数天生都是闭包的 即JavaScirpt中的函数会自动通过隐藏[[Environment]]属性记住创建它们的位置 所以它们都可以访问外部变量
垃圾回收
通常,函数调用完成后,会将词法环境和其中的所有变量从内存中删除。因为现在没有任何对它们的引用了。与 JavaScript 中的任何其他对象一样,词法环境仅在可达时才会被保留在内存中。
但是 如果有一个嵌套函数在函数结束后的语句任然可达 则它将具有引用词法环境的 [[Environment]] 属性。
1 | function f() { |
如果多次调用 f(),并且返回的函数被保存,那么所有相应的词法环境对象也会保留在内存中。下面代码中有三个这样的函数:
1 | function f() { |
当词法环境对象变得不可达时,它就会死去(就像其他任何对象一样)。换句话说,它仅在至少有一个嵌套函数引用它时才存在。
在下面的代码中,嵌套函数被删除后,其封闭的词法环境(以及其中的 value)也会被从内存中删除:
1 | function f() { |
全局对象和函数对象
全局对象
全局对象提供可以在任何地方都使用的变量和函数 默认的情况下这些全局变量内建于语言或环境中
在浏览器环境中 全局对象是window 对于nodejs运行时环境 全局对象是global
在最新的规定中globalThis 被作为全局对象的标准名称加入到了 JavaScript 中,所有环境都应该支持该名称。所有主流浏览器都支持它。
全局对象的所有属性都可以直接被访问
1 | alert('hello') |
在浏览器中 使用var声明的全局函数和变量都会成为全局属性
1 | var gVar = 10 |
请不要这样去使用!这种行为是出于兼容性而存在的。现代脚本使用 JavaScript modules 所以不会发生这种事情。
如果我们使用 let,就不会发生这种情况
如果一个值非常重要你想让它在全局的范围中
1 | // 将当前用户信息全局化,以允许所有脚本访问它 |
函数对象
在 JavaScript 中函数也是一个值,函数值的类型是 object
可以把函数理解成为一个可调用的行为对象(action object) 同样可以传递属性和引用传递
比如属性 name
1 | function sayHi() { |
规范中把这种特性叫做「上下文命名」。如果函数自己没有提供,那么在赋值中,会根据上下文来推测一个。
1 | let user = { |
属性 length
1 | function f1(a) {} |
属性 length 有时在操作其它函数的函数中用于做 内省/运行时检查(introspection)
1 | function ask(question, ...handlers) { |
自定义属性
我们可以在函数中添加counter属性记录被调用了多少次
1 | function sayHi() { |
属性并不是变量,被赋值给函数的属性,比如 sayHi.counter = 0,不会 在函数内定义一个局部变量 counter。换句话说,属性 counter 和变量 let counter 是毫不相关的两个东西。
函数属性有时会用来替代闭包 如下面修改之前写过的闭包
1 | function makeCounter() { |
即count被直接存储在函数里,而不是它外部的词法环境
这种写法一般不太常见 因为可以在外部去修改它的属性 从而导致代码很混乱
1 | function makeCounter() { |
命名函数的表达式
命名函数表达式(NFE, Named Function Expression) 指带有名字的函数表达式术语
1 | let sayHi = function func(who) { |
它仍然是一个函数表达式。在 function 后面加一个名字 "func" 没有使它成为一个函数声明,因为它仍然是作为赋值表达式中的一部分被创建的。
添加这个名字当然也没有打破任何东西。函数依然可以通过 sayHi() 来调用:
关于添加func的两个特殊的地方
- 允许函数在内部引用自己
- 它在函数外是引用不到的
1 | let sayHi = function func(who) { |
同样不适用sayHi()去写递归 因为 sayHi()很容易就被外部污染
1 | let sayHi = function (who) { |
当我们需要一个可靠的内部名时,这就成为了你把函数声明重写成函数表达式的理由了。
调度:setTimeout 和 setInterval
当我们并不想立刻执行一个函数,而是等待特定一段时间之后再执行。这就是所谓的“计划调用(scheduling a call)”。
目前的实现方式有下面两种方式实现
setTimeout: 允许我们将函数推迟到一段时间间隔之后再执行setInterval: 允许我们重复运行一个函数,从一段时间间隔之后开始运行,之后以该时间间隔连续重复运行该函数。
setTimeout
1 | let sayHi = function (who) { |
setTimeout 期望得到一个对函数的引用
clearTimeout 来取消调度
setTimeout 在调用时会返回一个“定时器标识符(timer identifier)”,在我们的例子中是 timerId,我们可以使用它来取消执行。
1 | let timerId = setTimeout(...); |
setInterval
setInterval 方法和 setTimeout 的语法相同:不过与 setTimeout 只执行一次不同,setInterval 是每间隔给定的时间周期性执行。
装饰器模式和转发:Call/apply
JavaScript在处理函数时提供了很高的灵活性,它们可以被传递 用作对象 下面将介绍它们之间的转发(forward)和装饰(decorate)
透明缓存
假设现在我们有一个 CPU 重负载的函数slow(x) 但是他纯函数 给定相同的参数总是会返回相同的结果 如果这个函数使用频繁 我们希望能记住这个缓存能记住 因此避免花费额外的时间 如下
1 | function slow(x) { |
在上面的例子中 cachingDecorator是一个装饰器(decorator)
这样我们可以为任何函数调用cachingDecorator 它将返回缓存包装器 这样别的函数需要这种特性就可以直接复用 还可以将缓存与主代码分开变得更加简单
cachingDecorator(func) 的结果是一个“包装器”:function(x) 将 func(x) 的调用“包装”到缓存逻辑中 从外部代码来看,包装的 slow 函数执行的仍然是与之前相同的操作。它只是在其行为上添加了缓存功能。
使用分离的 cachingDecorator 而不是改变 slow 本身的代码有几个好处
cachingDecorator是可重用的。我们可以将它应用于另一个函数。- 缓存逻辑是独立的,它没有增加
slow本身的复杂性(如果有的话)。 - 如果需要,我们可以组合多个装饰器(其他装饰器将遵循同样的逻辑)。
function.call 设定上下文
但是如果我们在对象中这样使用的话呢 如下
1 | let worker = { |
错误在于试图访问this.someMethod失败了 原因是包装器将原始函数调用为 (*step*) 行中的 func(x)。但是这样调用得到的this=undefined 这是因为包装器将调用传递给原始方法 但是并没有上下文的this
使用内建的函数方法function.call(context,...args)允许调用一个显示设置的this函数
例如,在下面的代码中,我们在不同对象的上下文中调用 sayHi:sayHi.call(user) 运行 sayHi 并提供了 this=user,然后下一行设置 this=admin
1 | function sayHi() { |
在我们的例子中,我们可以在包装器中使用 call 将上下文传递给原始函数:
1 | let worker = { |
现在一切工作正常 this的传递过程
- 在经过装饰之后,
worker.slow现在是包装器function (x) { ... }。 - 因此,当
worker.slow(2)执行时,包装器将2作为参数,并且this=worker(它是点符号.之前的对象)。 - 在包装器内部,假设结果尚未缓存,
func.call(this, x)将当前的this(=worker)和当前的参数(=2)传递给原始方法。
传递多个参数
记住参数组合(min,max)的结果
- 实现一个新的类似于 map 的更通用的并且允许多个键的数据结构
- 使用嵌套的 map 去实现比如
map.get(min).get(max)来获取 result - 将两个值合并成一个 多为装饰器添加一个函数
现在以第三种方法写出带多个参数
1 | let worker = { |
现在这个包装器可以处理任意数量的参数了
- 在
(**)行中它调用hash来从arguments创建一个单独的键。这里我们使用一个简单的“连接”函数,将参数(3, 5)转换为键"3,5"。更复杂的情况可能需要其他哈希函数。 - 然后
(***)行使用func.call(this, ...arguments)将包装器获得的上下文和所有参数(不仅仅是第一个参数)传递给原始函数。
function.apply
apply 和 call的用法类似 区别就是 apply 希望接受的是一个参数列表而不是多个参数
1 | function.call(this,...args) === function.apply(this,args) |
装饰器和属性函数
通常,用装饰的函数替换一个函数或一个方法是安全的,除了一件小东西。如果原始函数有属性,例如 func.calledCount 或其他,则装饰后的函数将不再提供这些属性。因为这是装饰器。因此,如果有人使用它们,那么就需要小心。
例如,在上面的示例中,如果 slow 函数具有任何属性,而 cachingDecorator(slow) 则是一个没有这些属性的包装器。
一些包装器可能会提供自己的属性。例如,装饰器会计算一个函数被调用了多少次以及花费了多少时间,并通过包装器属性公开(expose)这些信息。
存在一种创建装饰器的方法,该装饰器可保留对函数属性的访问权限,但这需要使用特殊的 Proxy 对象来包装函数。
函数绑定
在将对象的方法作为回调进行传递 例如传递给setTimeout的时候 会存在一个常见的问题即是丢失this
比如下面的情况
1 | let user = { |
这是因为setTimeout获取到了函数user.sayHi 但是他和对象分开了 this丢失了
解决办法 1 用函数包括执行
1 | let user = { |
这样即可以成功
但是这样又会存在 可能在定时器还在计时的过程中如果 sayHi() 函数发生变化 那么又会调用到错误的对象this
解决办法 2 bindfunc.bind(context)的结果是一个特殊的类似于函数的“外来对象”,它可以像函数一样被调用,并且透明地将调用传递给 func 并设定 this=context。
如下
1 | let user = { |
上面例子的解法
1 | let user = { |
箭头函数
箭头函数不仅仅是编写简介代码的”捷径” 还具有非常特殊有用的特性
JavaScript 充满了我们需要编写在其他地方执行的小函数的情况
例如:
arr.forEach(func)每个元素都执行funcsetTimeout(func)由内建调度器执行- ….
JavaScript 的精髓在于创建一个函数并将其传递到某个地方。
在这样的函数中,我们通常不想离开当前上下文。这就是箭头函数的应用场景
箭头函数没有 this
1 | let group = { |
这里forEach中使用了箭头函数 其中的this.title 其实和外部方法showList完全一样
如果我们使用正常的函数 则会出现错误
1 | let group = { |
报错是因为 forEach 运行它里面的这个函数,但是这个函数的 this 为默认值 this=undefined,因此就出现了尝试访问 undefined.title 的情况。但箭头函数就没事,因为它们没有 this。
warning 不能对箭头函数进行new操作 不具有this自然就意味着箭头函数不能作为构造(constructor)器
箭头函数没有 arguments
箭头函数也没有arguments变量
对象
属性标志和属性描述符
我们知道 对象可以存储属性到目前为止,属性对我们来说只是一个简单的“键值”对。但对象属性实际上是更灵活且更强大的东西。
属性标志
对象属性(properties) 是除了value 还有三个特殊的特性(attributes) 即标志
writable如果是true则值可以被修改 否则它是只可读的enumerable如果是true则值可以被枚举 否则不会被列出。configurable— 如果为true,则此属性可以被删除,这些特性也可以被修改,否则不可以。
Object.getOwnPropertyDescriptor方法允许查询有关属性的完整信息
1 | let user = { |
为了修改标志,我们可以使用Object.defineProperty
使用的语法是Object.defineProperty(obj,propertyName,descriptor)
obj,propertyName 要应用描述符的对象及其属性 descriptor要应用的属性描述符对象
如果该属性存在,defineProperty 会更新其标志。否则,它会使用给定的值和标志创建属性;在这种情况下,如果没有提供标志,则会假定它是 false。
1 | let user = {} |
将它与上面的“以常用方式创建的” user.name 进行比较:现在所有标志都为 false。如果这不是我们想要的,那么我们最好在 descriptor 中将它们设置为 true。
可以设置属性为: 只读 不可枚举 不可配置
Object.defineProperties
1 | Object.defineProperties(user, { |
设定一个全局的密封对象
禁止向对象添加新属性。
禁止添加/删除属性。为所有现有的属性设置
configurable: false。禁止添加/删除/更改属性。为所有现有的属性设置
configurable: false, writable: false。
还有针对它们的测试:
如果添加属性被禁止,则返回
false,否则返回true。如果添加/删除属性被禁止,并且所有现有的属性都具有
configurable: false则返回true。如果添加/删除/更改属性被禁止,并且所有当前属性都是
configurable: false, writable: false,则返回true。
对象属性配置
getter 和 setter
有两种类型的对象属性。
第一种是 数据属性。我们已经知道如何使用它们了。到目前为止,我们使用过的所有属性都是数据属性。
第二种类型的属性是新东西。它是 访问器属性(accessor property)。它们本质上是用于获取和设置值的函数,但从外部代码来看就像常规属性。
访问器属性由 “getter” 和 “setter” 方法表示。在对象字面量中,它们用 get 和 set 表示:
1 | let obj = { |
当读取 obj.propName 时,getter 起作用,当 obj.propName 被赋值时,setter 起作用。
例如,我们有一个具有 name 和 surname 属性的对象 user:
1 | let user = { |
从外表看,访问器属性看起来就像一个普通属性。这就是访问器属性的设计思想。我们不以函数的方式 调用 user.fullName,我们正常 读取 它:getter 在幕后运行。
让我们通过为 user.fullName 添加一个 setter 来修改它:
1 | let user = { |
访问器描述符
访问器属性的描述符与数据属性的不同。
对于访问器属性,没有 value 和 writable,但是有 get 和 set 函数。
所以访问器描述符可能有:
get—— 一个没有参数的函数,在读取属性时工作,set—— 带有一个参数的函数,当属性被设置时调用,enumerable—— 与数据属性的相同,configurable—— 与数据属性的相同。
例如上面的例子使用defineProperty创建一个fullName访问器
1 | let user = { |
请注意,一个属性要么是访问器(具有 get/set 方法),要么是数据属性(具有 value),但不能两者都是。
如果我们试图在同一个描述符中同时提供 get 和 value,则会出现错误:
1 | // Error: Invalid property descriptor. |
原型
在编程中我们经常会想获取并扩展一些东西
比如我们有一个user对象及其属性和方法,并希望将 admin 和 guest 作为基于 user 稍加修改的变体。我们想重用 user 中的内容,而不是复制/重新实现它的方法,而只是在其之上构建一个新的对象。
原型继承(Prototypal inheritance) 这个语言特性能够帮助我们实现这一需求。
Prototype
在 JavaScript 中 对象有特殊的隐藏属性[[Prototype]] 他们要么是null 要么就是在另一个对象中的引用 该对象称之为原型
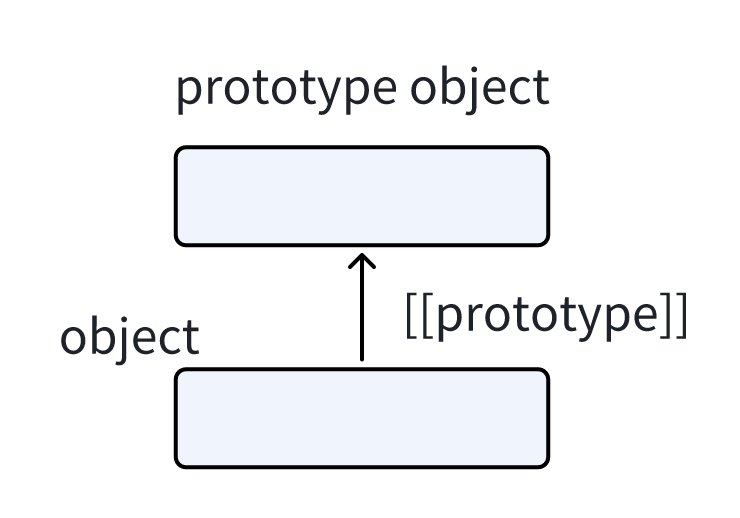
我们会从Object逐步的向上寻找 即原型继承属性 [[Prototype]] 是内部的而且是隐藏的,但是这儿有很多设置它的方式。其中之一就是使用特殊的名字 __proto__,就像这样:
1 | let animal = { |
原型链可能会很长
1 | let animal = { |
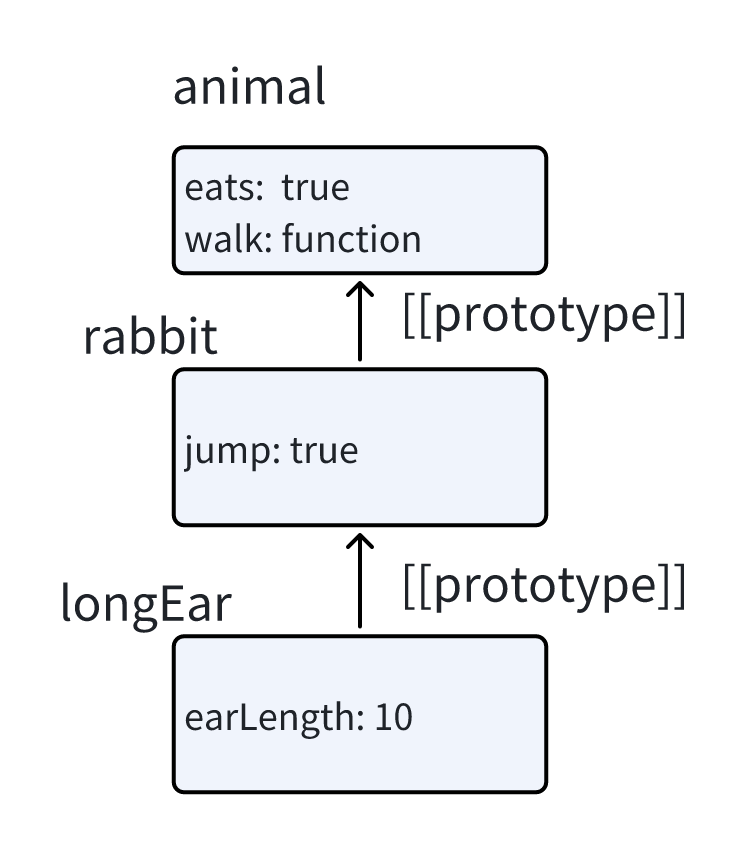
现在,如果我们从 longEar 中读取一些它不存在的内容,JavaScript 会先在 rabbit 中查找,然后在 animal 中查找。
这里只有两个限制:
- 引用不能形成闭环。如果我们试图给
__proto__赋值但会导致引用形成闭环时,JavaScript 会抛出错误。 __proto__的值可以是对象,也可以是null。而其他的类型都会被忽略。
当然,这可能很显而易见,但是仍然要强调:只能有一个 [[Prototype]]。一个对象不能从其他两个对象获得继承。
注意:
__proto__是[[Prototype]]的因历史原因而留下来的 getter/setter__proto__与内部的[[Prototype]]不一样__proto__是[[Prototype]]的 getter/setter。__proto__属性有点过时了。它的存在是出于历史的原因,现代编程语言建议我们应该使用函数Object.getPrototypeOf/Object.setPrototypeOf来取代__proto__去 get/set 原型
原型仅用于读取属性上,赋值操作是由setter函数去处理而 因此写入类属性实际上就是与调用函数相同
1 | let user = { |
Object.key(obj)只会遍历当前的属性的值
for in 会遍历当前的和继承的值 如果要判断是否是自己的可以使用obj.hasOwnPropetry
总结
- 在 JavaScript 中,所有的对象都有一个隐藏的
[[Prototype]]属性,它要么是另一个对象,要么就是null。 - 我们可以使用
obj.__proto__访问它(历史遗留下来的 getter/setter,这儿还有其他方法,很快我们就会讲到)。 - 通过
[[Prototype]]引用的对象被称为“原型”。 - 如果我们想要读取
obj的一个属性或者调用一个方法,并且它不存在,那么 JavaScript 就会尝试在原型中查找它。 - 写/删除操作直接在对象上进行,它们不使用原型(假设它是数据属性,不是 setter)。
- 如果我们调用
obj.method(),而且method是从原型中获取的,this仍然会引用obj。因此,方法始终与当前对象一起使用,即使方法是继承的。 for..in循环在其自身和继承的属性上进行迭代。所有其他的键/值获取方法仅对对象本身起作用。
F.prototype
我们可以通过new F()这样的构造函数来创建一个新对象
如果F.prototype是一个对象, new操作符会使用它作为新对象设置[[Prototype]]
这里的F.prototype指的是F的一个prototype的普通(常规)属性 如下
1 | let animal = { |
设置 Rabbit.prototype = animal 的字面意思是:“当创建了一个 new Rabbit 时,把它的 [[Prototype]] 赋值为 animal”。
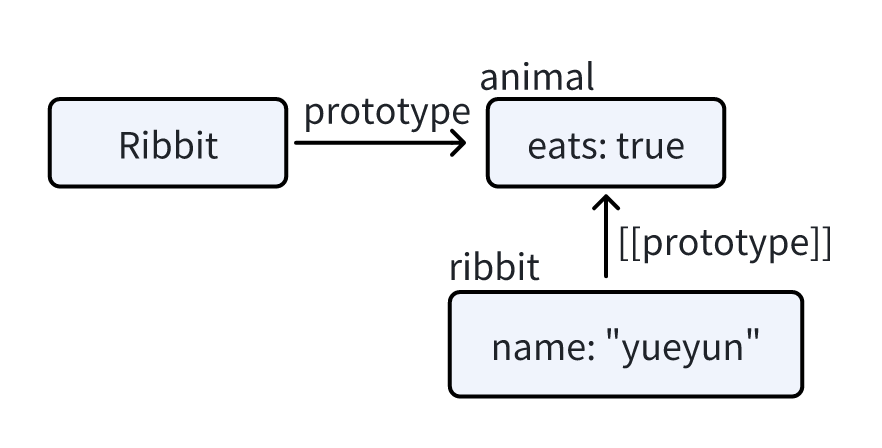
在上图中,"prototype" 是一个水平箭头,表示一个常规属性,[[Prototype]] 是垂直的,表示 rabbit 继承自 animal。
F.prototype仅用在new F被调用时使用 它为新对象的[[Prototype]]赋值
默认的 F.prototype 构造器属性
每个函数都有 "prototype" 属性,即使我们没有提供它。默认的 "prototype" 是一个只有属性 constructor 的对象,属性 constructor 指向函数自身。
1 | function Rabbit() {} |
F.prototype属性(不要把它与[[Prototype]]弄混了)在new F被调用时为新对象的[[Prototype]]赋值。F.prototype的值要么是一个对象,要么就是null:其他值都不起作用。"prototype"属性仅当设置在一个构造函数上,并通过new调用时,才具有这种特殊的影响。
原生的原型
prototype属性在 JavaScript 中广泛的使用 所有而内建构造函数都使用到了它
Object.prototype
1 | let obj = {} |
内建的toString生成了字符串[object object] obj = {} 和 obj = new Object() 是一个意思,其中 Object 就是一个内建的对象构造函数,其自身的 prototype 指向一个带有 toString 和其他方法的一个巨大的对象。
1 | let obj = {} |
其他内建原型
例如: Array Date Function及其他,都在prototype上挂载了方法
当我们创建一个数组 [1, 2, 3],在内部会默认使用 new Array() 构造器。因此 Array.prototype 变成了这个数组的 prototype,并为这个数组提供数组的操作方法。这样内存的存储效率是很高的。所有的内建原型顶端都是 Object.prototype。这就是为什么有人说“一切都从对象继承而来”。
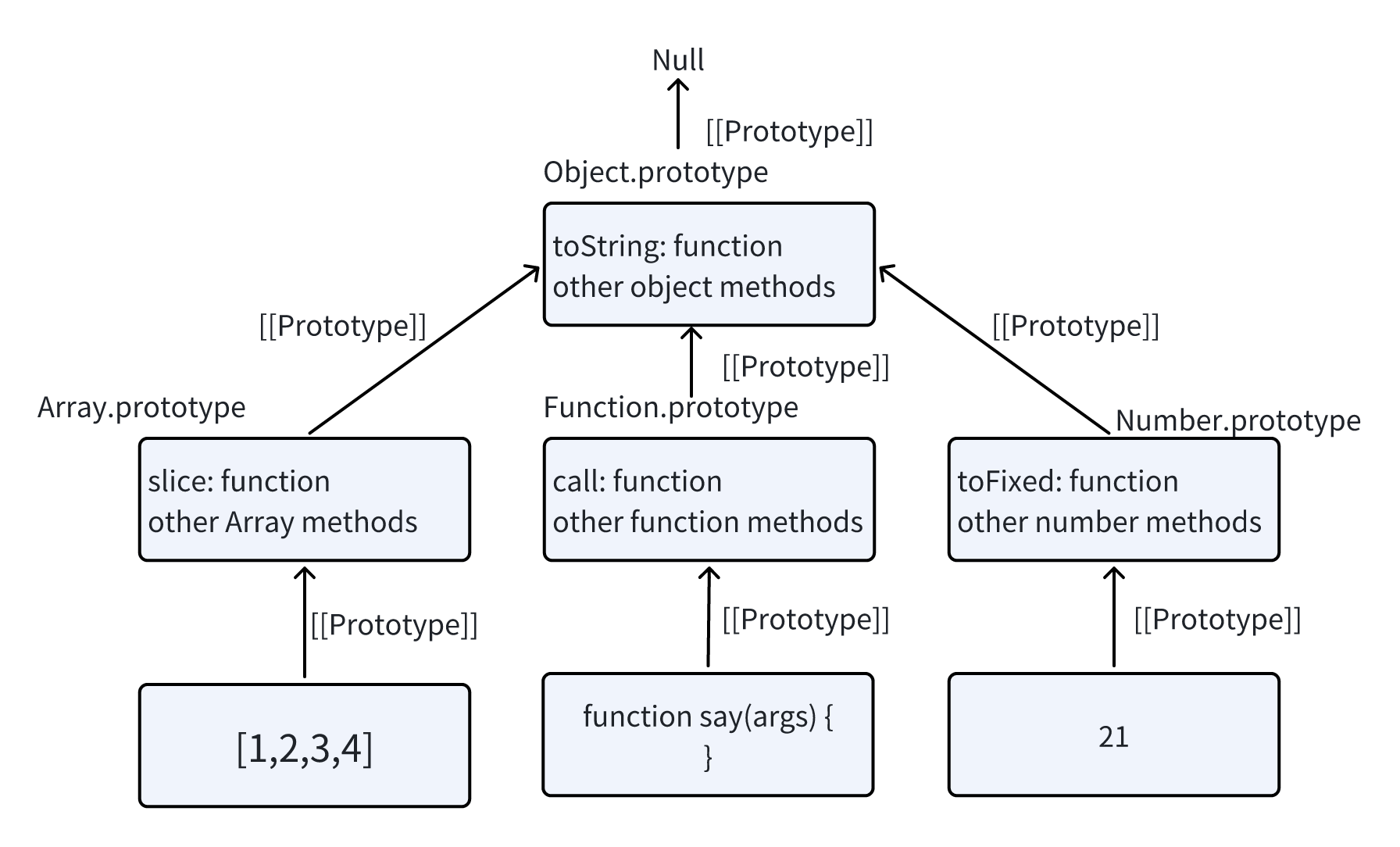
经过下面验证
1 | let arr = [1, 2, 3] |
一些方法在原型上可能会发生重叠,例如,Array.prototype 有自己的 toString 方法来列举出来数组的所有元素并用逗号分隔每一个元素。
基本数据类型
最复杂的事情发生在字符串、数字和布尔值上。
正如我们记忆中的那样,它们并不是对象。但是如果我们试图访问它们的属性,那么临时包装器对象将会通过内建的构造器 String、Number 和 Boolean 被创建。它们提供给我们操作字符串、数字和布尔值的方法然后消失。
这些对象对我们来说是无形地创建出来的。大多数引擎都会对其进行优化,但是规范中描述的就是通过这种方式。这些对象的方法也驻留在它们的 prototype 中,可以通过 String.prototype、Number.prototype 和 Boolean.prototype 进行获取。
值null和undefined没有对象包装器.并且它们也没有相应的原型。
更改原生原型
在开发的过程中,我们可能会想要一些新的内建方法,并且想把它们添加到原生原型中。但这通常是一个很不好的想法。
原型是全局的,所以很容易造成冲突。如果有两个库都添加了
String.prototype.show方法,那么其中的一个方法将被另一个覆盖。所以,通常来说,修改原生原型被认为是一个很不好的想法。
类
class 语法
1 | class MyClass { |
通过new MyClass()来创建具有上述方法的新对象
new 会自动调用 constructor() 方法,因此我们可以在 constructor() 中初始化对象。
1 | class MyClass { |
在JavaScript中 类其实是一种函数 在ES6中增加了类而关键字是一种新的语法糖放其更加方便直观的创建想要的类
1 | class User { |
class User{...}构造实际是完成了下面的事
- 创建一个名为
User的函数 该函数为类声明的结果 该函数的代码来自于constructor方法 - 存储类中的方法 例如
User.prototype中的sayHi
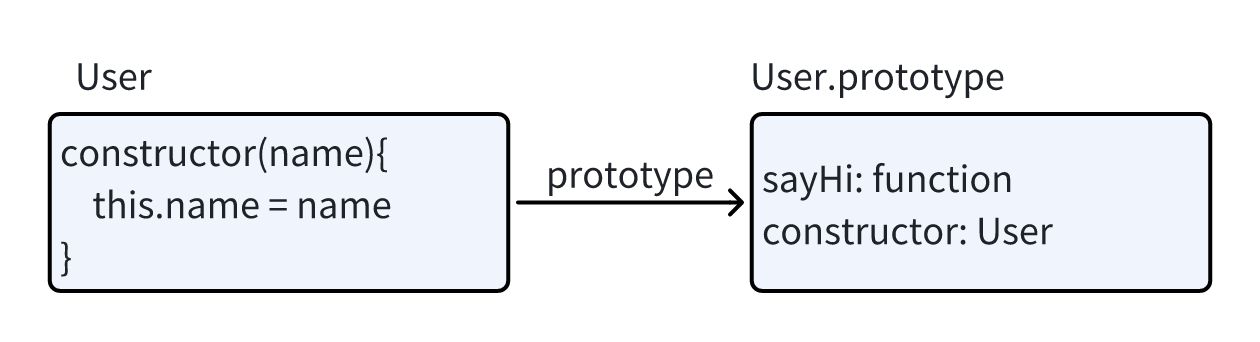
如下面的代码解释
1 | class User { |
错误处理
try catch
通常我们在编写脚本的时候总是会遇到很多非预期的错误 导致脚本停止执行,有一种语法结构 try...catch,它使我们可以“捕获(catch)”错误,因此脚本可以执行更合理的操作,而不是死掉。
1 | try { |
- 首先执行
try {...}中的代码 - 如果没有错误,那么就跳过
catch(err)中的代码,继续执行,try中的代码执行完毕 - 如果出现错误,那么
try中剩下的代码停止执行,控制台执行catch(err)中的代码,catch中的代码将包含一个error 的对象执行完毕
Error对象
发生错误时,JavaScript 会生成一个包含有关此 error 详细信息的对象。然后将该对象作为参数传递给 catch:
1 | try { |
name: Error的名称 例如一个未定义的变量则报错是ReferenceErrormessage: 关于error的详细文字描述stack: 当前的单调栈 用于调试
抛出自定义的Error
throw操作符
throw操作符会生成一个error对象
1 | throw <error object> |
技术上讲,我们可以将任何东西用作 error 对象。甚至可以是一个原始类型数据,例如数字或字符串,但最好使用对象,最好使用具有 name 和 message 属性的对象(某种程度上保持与内建 error 的兼容性)。JavaScript 中有很多内建的标准 error 的构造器:Error,SyntaxError,ReferenceError,TypeError 等。我们也可以使用它们来创建 error 对象。
1 | let error = new Error(message); |
再次抛出(Rethrowing)
1 | let json = '{ "age": 30 }'; // 不完整的数据 |
try…catch…finally
try...catch 结构可能还有一个代码子句(clause):finally。
1 | try { |
自定义Error,扩展Error
当我们开发项目时,经常需要我们自己定义error类来反映任务中可能出错的特定任务, 对于网络操作中的error 我们需要HttpError 对于数据库操作中的error 我们需要DbError,对于搜索操作的error 我们需要NotFoundError
我们自定义的 error 应该支持基本的 error 的属性,例如 message,name,并且最好还有 stack。但是它们也可能会有其他属于它们自己的属性,例如,HttpError 对象可能会有一个 statusCode 属性,属性值可能为 404、403 或 500 等。
扩展Error
如果我们需要使用json去检查是否存在某个数据我们现在规定成ValidationError
Error类是内建的 结构类似如下
1 | // JavaScript 自身定义的内建的 Error 类的“伪代码” |
现在让我们从其中继承 ValidationError,并尝试进行运行:
1 | class ValidationError extends Error { |
深入继承
ValidationError类是非常通用的 很多东西都可能出错 对象的属性可能缺失或者属性可能有格式错误,让我们针对缺少属性的错误来制作一个更具体的 PropertyRequiredError 类。它将携带有关缺少的属性的相关信息。
1 | class ValidationError extends Error { |
这个新的类 PropertyRequiredError 使用起来很简单:我们只需要传递属性名:new PropertyRequiredError(property)。人类可读的 message 是由 constructor 生成的。
1 | class MyError extends Error { |
迭代器
generator
常规函数只会返回一个单一值 (或者不返回任何值)
而 generator 可以按需一个接一个地返回yield多个值。它们可与iterable完美配合使用,从而可以轻松地创建数据流。
generator函数
要创建一个generator 我们需要一个特殊语法结构: function * 即所谓的generator function
1 | function* generateSequence () { |
generator函数与常规函数的行为不同 在此类函数被调用时 他不会运行其代码.而是返回一个被称为 “generator object” 的特殊对象,来管理执行流程。
1 | function* generateSequence(){ |
到现在为止 上段代码中的函数体代码并没有开始执行
一个 generator 的主要方法就是 next()。当被调用时,它会恢复运行,执行直到最近的 yield <value> 语句(value 可以被省略,默认为 undefined)。然后函数执行暂停,并将产出的(yielded)值返回到外部代码。
next()的结果始终是一个具有两个属性的对象:
value: 产出的(yielded)的值done: 如果generator函数已执行完成则为true否则为false
1 | function* generateSequence() { |
模块导入导出
异步
回调
简介: 回调
JavaScript环境提供了许多内置的函数 这些函数允许执行异步行为,我们现在开始执行的行为,但它们会在稍后完成。
比如经常用的setTimeout函数就是这样的函数 比如函数loadScript(src)
1 | function loadScript (src) { |
它将一个新的、带有给定 src 的、动态创建的标签 <script src="…"> 插入到文档中。浏览器将自动开始加载它,并在加载完成后执行它。
脚本是异步调用的 因为它从现在开始加载 在加载函数执行完成后才运行
如果在 loadScript(…) 下面有任何其他代码,它们不会等到脚本加载完成才执行。
如果现在我们有一个需求是脚本加载后立即使用它 它声明了一个新函数 我们想运行它 如果在loadSrript(...) 后立刻运行则会报错
1 | loadScript('/my/script.js'); // 这个脚本有 "function newFunction() {…}" |
自然情况下 浏览器没有时间加载脚本为了解决这个办法我们可以添加一个callback 函数作为loadScript的第二个参数 该函数应用在脚本加载完成时执行
1 | function loadScript(src,callback){ |
比如下面的案例
1 | function loadScript(src, callback) { |
这被称为“基于回调”的异步编程风格。异步执行某项功能的函数应该提供一个 callback 参数用于在相应事件完成时调用。
回调中的回调
我们如何依次加载两个脚本:第一个,然后是第二个?
自然的解决方案是将第二个 loadScript 调用放入回调中,如下所示:
1 | loadScript('/my/script.js', function(script) { |
因此,每一个新行为(action)都在回调内部。这对于几个行为来说还好,但对于许多行为来说就不好了,所以我们很快就会看到其他变体。
处理Error
我们并没有考虑出现 error 的情况。如果脚本加载失败怎么办?我们的回调应该能够对此作出反应。这是 loadScript 的改进版本,可以跟踪加载错误:
1 | function loadScript(src, callback) { |
在 loadScript 中所使用的方案其实很普遍。它被称为“Error 优先回调(error-first callback)”风格。
callback的第一个参数是为 error 而保留的。一旦出现 error,callback(err)就会被调用。- 第二个参数(和下一个参数,如果需要的话)用于成功的结果。此时
callback(null, result1, result2…)就会被调用。
单一的 callback 函数可以同时具有报告 error 和传递返回结果的作用。
回调地狱
当有很复杂的逻辑的时候一个接一个的异步行为
1 | loadScript('1.js', function(error, script) { |
在上面这段代码中:
- 我们加载
1.js,如果没有发生错误。 - 我们加载
2.js,如果没有发生错误…… - 我们加载
3.js,如果没有发生错误 —— 做其他操作(*)。
随着调用嵌套的增加,代码层次变得更深,维护难度也随之增加,尤其是我们使用的是可能包含了很多循环和条件语句的真实代码,而不是例子中的 ...。
避免金字塔 最好的方法之一就是promise
Promise
生产者: executor
Promise 对象的构造器(constructor) 语法如下
1 | let promise = new Promise(function (resolve,reject) { |
传递给new Promise的函数被称之为executor 当new Promise被创建 executor 会自动运行它包含最终应产出结果的生产者代码
它的参数 resolve 和 reject 是由 JavaScript 自身提供的回调。我们的代码仅在 executor 的内部
当 executor 获得了结果,无论是早还是晚都没关系,它应该调用以下回调之一:
resolve(value)- 如果任务成功完成并带有结果valuereject(error)- 如果出现了errorerror即为error 对象
executor会自动运行并尝试执行一项工作 尝试结束后 如果成功则调用resolve 如果出现error则调用reject
有new Promise构造器返回的promise对象具有以下内部属性
state– 最初是pending 然后在resolve被调用时变为fulfilled或者在reject被调用时变成rejectedresult最初是undefined 然后在resovle(value)被调用时变为value或者在reject(error)被调用时变成error
所以,executor 最终将 promise 移至以下状态之一
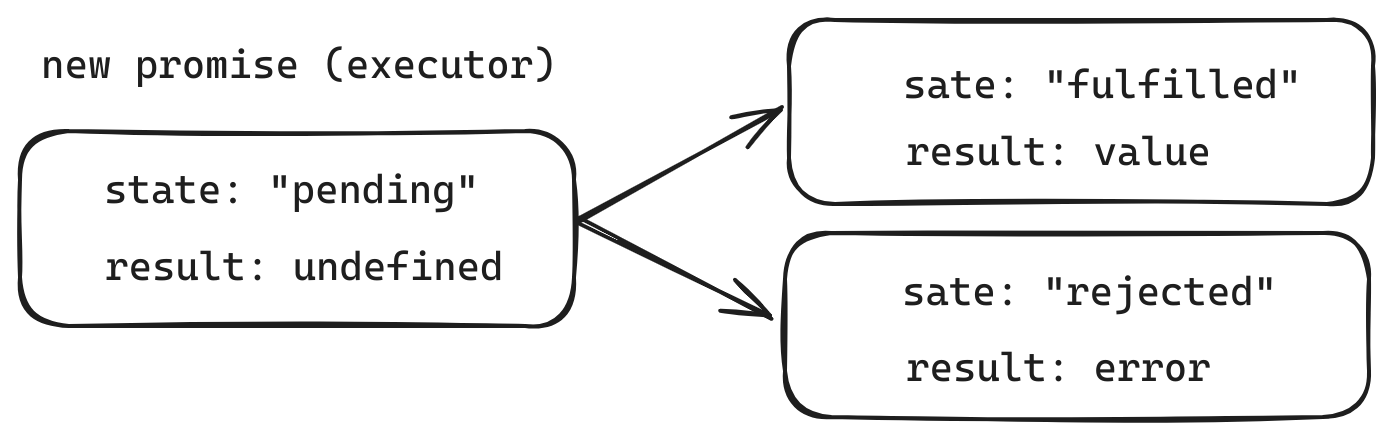
下面是一个 promise 构造器和一个简单的 executor 函数,该 executor 函数具有包含时间(即 setTimeout)的“生产者代码”:
1 | let promise = new Promise(function(resolve,reject) { |
- executor 被自动且立即调用 (通过
new Promise) - executor 接受两个参数:
resolve和reject这些函数由JavaScript引擎预先定义的函数
经过 1 秒的“处理”后,executor 调用 resolve("done") 来产生结果。这将改变 promise 对象的状态: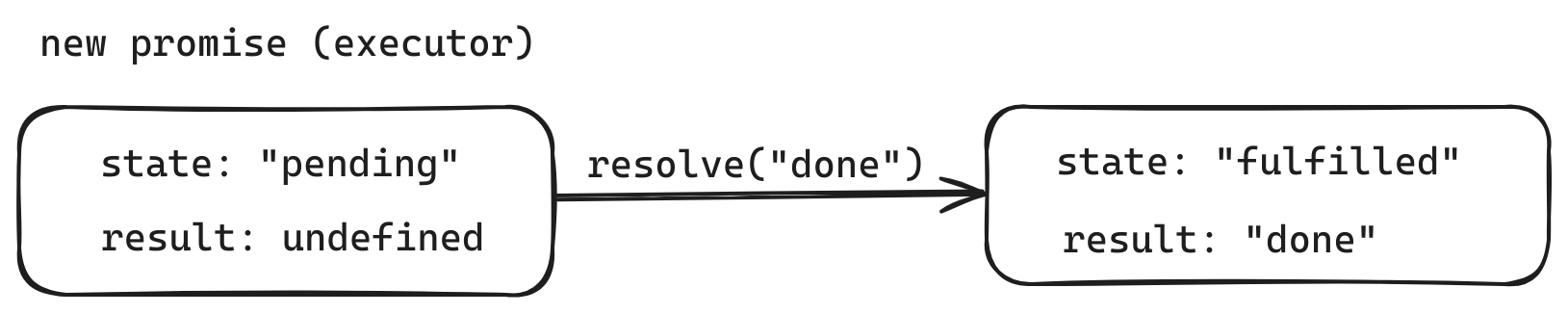
下面则是一个 executor 以 error 拒绝 promise 的示例:
1 | let promise = new Promise(function(resolve, reject) { |
对 reject(...) 的调用将 promise 对象的状态移至 "rejected":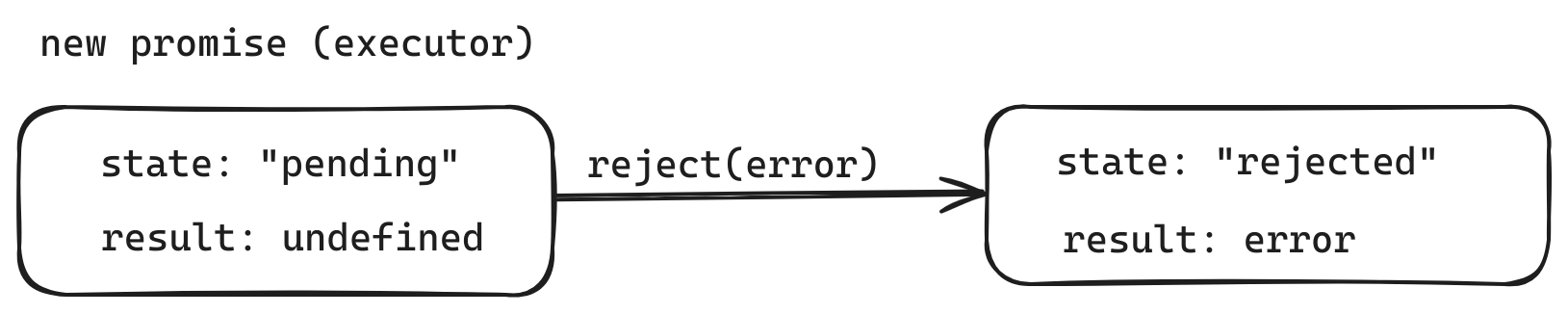
总而言之,executor 应该执行一项工作(通常是需要花费一些时间的事儿),然后调用 resolve 或 reject 来改变对应的 promise 对象的状态。
与最初的 “pending” promise 相反,一个 resolved 或 rejected 的 promise 都会被称为 “settled”。
executor 只能调用一个
resolve或一个reject任何状态的更改都是最终的 所有其他的再对resolve和reject的调用都会被忽略
2
3
4
5
6
7
resolve("done");
reject(new Error("…")); // 被忽略
setTimeout(() => resolve("…")); // 被忽略
});这的宗旨是,一个被 executor 完成的工作只能有一个结果或一个 error。
并且,
resolve/reject只需要一个参数(或不包含任何参数),并且将忽略额外的参数
消费者: then catch
then
语法如下
1 | promise.then( |
.then 的第一个参数是一个函数,该函数将在 promise resolved 且接收到结果后执行。
.then 的第二个参数也是一个函数,该函数将在 promise rejected 且接收到 error 信息后执行。
如果我们只对成功完成的情况感兴趣,那么我们可以只为 .then 提供一个函数参数:
1 | let promise = new Promise(resolve => { |
catche
如果我们只对 error 感兴趣,那么我们可以使用 null 作为第一个参数:.then(null, errorHandlingFunction)。或者我们也可以使用 .catch(errorHandlingFunction),其实是一样的
1 | let promise = new Promise((resolve, reject) => { |
.catch(f) 调用是 .then(null, f) 的完全的模拟,它只是一个简写形式。
清理: finally
就像常规 try {...} catch {...} 中的 finally 子句一样,promise 中也有 finally。
调用 .finally(f) 类似于 .then(f, f),因为当 promise settled 时 f 就会执行:无论 promise 被 resolve 还是 reject。
finally 的功能是设置一个处理程序在前面的操作完成后,执行清理/终结。
例如,停止加载指示器,关闭不再需要的连接等。
1 | new Promise((resolve, reject) => { |
示例: loadScript
1 | function loadScript(src) { |
Promise链
promise链如下
1 | new Promise(function(resolve, reject) { |
通过.then处理程序(handler)链进行传递result
运行流程如下:
- 初始 promise 在 1 秒后 resolve
(*), - 然后
.then处理程序被调用(**),它又创建了一个新的 promise(以2作为值 resolve)。 - 下一个
then(***)得到了前一个then的值,对该值进行处理(*2)并将其传递给下一个处理程序。 - ……依此类推。
随着 result 在处理程序链中传递,我们可以看到一系列的 alert 调用:1 → 2 → 4。
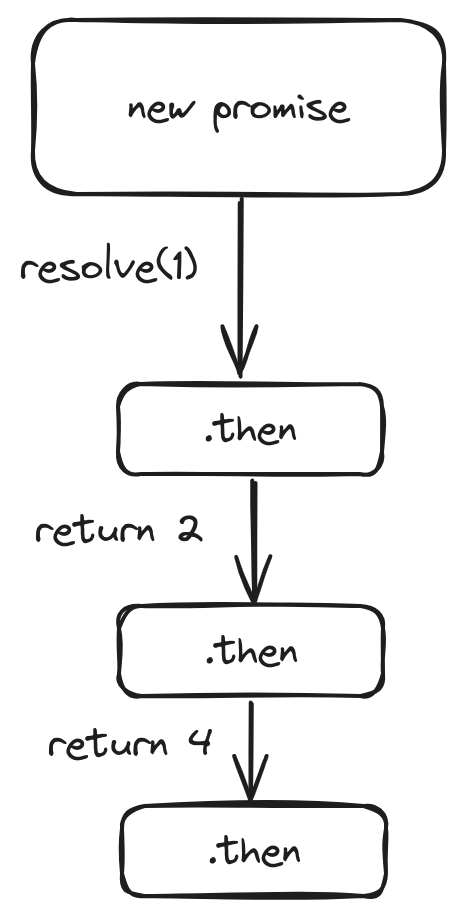
这样之所以是可行的,是因为每个对 .then 的调用都会返回了一个新的 promise,因此我们可以在其之上调用下一个 .then。
返回Promise
.then(handler) 中所使用的处理程序(handler)可以创建并返回一个 promise。
在这种情况下,其他的处理程序将等待它 settled 后再获得其结果。
1 | loadScript("/article/promise-chaining/one.js") |
示例: fetch
在前端编程中,promise 通常被用于网络请求 使用fetch方法
1 | fetch('/article/promise-chaining/user.json') |
例如,我们可以再向 GitHub 发送一个请求,加载用户个人资料并显示头像:
1 | function loadJson(url) { |
如果 .then(或 catch/finally 都可以)处理程序返回一个 promise,那么链的其余部分将会等待,直到它状态变为 settled。当它被 settled 后,其 result(或 error)将被进一步传递下去。
Promise API
Promise.all
我们希望并行执行多个 promise, 并等待所有 promise 都准备就绪
例如,并行下载几个 URL,并等到所有内容都下载完毕后再对它们进行处理。
1 | Promise.all([ |
数组中的元素顺序与源promise中的顺序相同 即使第一个 promise 花费了最长的时间才 resolve,但它仍是结果数组中的第一个。
如下
1 | let names = ['iliakan', 'remy', 'jeresig']; |
如果任意一个 promise 被 reject,由 Promise.all 返回的 promise 就会立即 reject,并且带有的就是这个 error。
如果出现 error,其他 promise 将被忽略
Promise.all(iterable)允许在iterable中使用非 promise 的“常规”值
Promise.allSettled
这是一个最近添加到 JavaScript 的特性。 旧式浏览器可能需要 polyfills.
如果任意的 promise reject,则 Promise.all 整个将会 reject。当我们需要 所有 结果都成功时,它对这种“全有或全无”的情况很有用:
1 | Promise.all([ |
Promise.allSettled 等待所有的 promise 都被 settle,无论结果如何。结果数组具有:
{status:"fulfilled", value:result}对于成功的响应,{status:"rejected", reason:error}对于 error。
例如,我们想要获取(fetch)多个用户的信息。即使其中一个请求失败,我们仍然对其他的感兴趣。
让我们使用 Promise.allSettled:
1 | let urls = [ |
Promise.race
与 Promise.all 类似,但只等待第一个 settled 的 promise 并获取其结果(或 error)。
1 | Promise.race([ |
这里第一个 promise 最快,所以它变成了结果。第一个 settled 的 promise “赢得了比赛”之后,所有进一步的 result/error 都会被忽略。
Promise.any
与 Promise.race 类似,区别在于 Promise.any 只等待第一个 fulfilled 的 promise,并将这个 fulfilled 的 promise 返回。如果给出的 promise 都 rejected,那么返回的 promise 会带有 AggregateError —— 一个特殊的 error 对象,在其 errors 属性中存储着所有 promise error。
Promise.resolve/reject
Promise.resolve(value)—— 使用给定 value 创建一个 resolved 的 promise。Promise.reject(error)—— 使用给定 error 创建一个 rejected 的 promise。
微任务(Microtask) – jobs
单线程JavaScript 基于事件循环 非阻塞IO型
事件循环中使用一个事件队列,在每个时间点上,系统只会处理一个事件,即使电脑有多个CPU核心,也无法同时并行的处理多个事件。因此,node.js在I/O型的应用中,给每一个输入输出定义一个回调函数,node.js会自动将其加入到事件轮询的处理队列里,当I/O操作完成后,这个回调函数会被触发,系统会继续处理其他的请求。
异步任务的回调会依次进入micro task queue,等待后续被调用,
- process.nextTick (Node独有)
- Promise
- Object.observe
- MutationObserver
宏任务(Macrotask) – tasks
异步任务的回调会依次进入macro task queue 等待后续被调用
- setTimeout
- setInterval
- setImmediate (Node)
- requestAnimationFrame (浏览器)
- I/O
- UI rendering
async/await
async 和 await 实际上就是语法糖 对于 Promise.resolve() 的语法糖 比如下面的例子
1 | async function async1() { |
输出顺序
1 | function fn(){ |
手写Promise A+
浏览器中的 JS
NodeJS
二进制数据、文件
ArrayBuffer、二进制数值
在web开发中 处理文件时(upload、download、create)时 经常会遇到二进制数据 处理头像的时候可能也会需要处理二进制数据 但是在JavaScript中有很多二进制数据的格式 比如
ArrayBufferUint8ArrayDataViewBlobFile等等…
基本的二进制对象是 ArrayBuffer —— 对固定长度的连续内存空间的引用。
1 | let buffer = new ArrayBuffer(16) |
它会分配一个 16 字节的连续内存空间,并用 0 进行预填充
ArrayBuffer 并不是数组
- 长度固定 无法增加和减少它的长度
- 正好占用了内存中的那么多的空间
- 要访问单个字节,需要另一个“视图”对象,而不是
buffer[index]。
ArrayBuffer 是一个内存区域 他里面储存了什么我们无法判断 只是一个原始的字节序列
如果需要去操作ArrayBuffer 我们需要去使用“试图”对象
试图对象本身并不存储任何东西 只是给我们提供一个操作的媒介去解释储存在ArrayBuffer中的字节 比如
- Uint8Array : 将
ArrayBuffer中的每个字节视为0到255之间的单个数字(每个字节是8位) 即8 位无符号整数 - Unit16Array:将每 2 个字节视为一个 0 到 65535 之间的整数。这称为 “16 位无符号整数”
Uint32Array—— 将每 4 个字节视为一个 0 到 4294967295 之间的整数。这称为 “32 位无符号整数”。Float64Array—— 将每 8 个字节视为一个5.0x10-324到1.8x10308之间的浮点数。
因此,一个 16 字节 ArrayBuffer 中的二进制数据可以解释为 16 个“小数字”,或 8 个更大的数字(每个数字 2 个字节),或 4 个更大的数字(每个数字 4 个字节),或 2 个高精度的浮点数(每个数字 8 个字节)。
Array是核心对象是所有的基础,是原始的二进制数据。
1 | let buffer = new ArrayBuffer(16) |
TypedArray
所有这些视图(Uint8Array,Uint32Array 等)的通用术语是 TypedArray。它们共享同一方法和属性集。
请注意,没有名为 TypedArray 的构造器,它只是表示 ArrayBuffer 上的视图之一的通用总称术语:Int8Array,Uint8Array 及其他
1 | new TypedArray(buffer, [byteOffset], [length]); |
如果给定的是
ArrayBuffer参数,则会在其上创建视图。我们已经用过该语法了。可选,我们可以给定起始位置
byteOffset(默认为 0)以及length(默认至 buffer 的末尾),这样视图将仅涵盖buffer的一部分。(ArryaBuffer 即是 buffer)如果给定的是
Array,或任何类数组对象,则会创建一个相同长度的类型化数组,并复制其内容。我们可以使用它来预填充数组的数据:
1
2
3let arr = new Uint8Array([0, 1, 2, 3]);
alert( arr.length ); // 4,创建了相同长度的二进制数组
alert( arr[1] ); // 1,用给定值填充了 4 个字节(无符号 8 位整数)如果给定的是另一个
TypedArray,也是如此:创建一个相同长度的类型化数组,并复制其内容。如果需要的话,数据在此过程中会被转换为新的类型。1
2
3
4let arr16 = new Uint16Array([1, 1000]);
let arr8 = new Uint8Array(arr16);
alert( arr8[0] ); // 1
alert( arr8[1] ); // 232,试图复制 1000,但无法将 1000 放进 8 位字节中
如要访问底层的 ArrayBuffer,那么在 TypedArray 中有如下的属性:
arr.buffer—— 引用ArrayBuffer。arr.byteLength——ArrayBuffer的长度。
1 | let arr8 = new Uint8Array([0, 1, 2, 3]); |
越界行为
如果我们尝试将越界值写入类型化数组会出现什么情况?不会报错。但是多余的位被切除。
例如,我们尝试将 256 放入 Uint8Array。256 的二进制格式是 100000000(9 位),但 Uint8Array 每个值只有 8 位,因此可用范围为 0 到 255。
对于更大的数字,仅存储最右边的(低位有效)8 位,其余部分被切除:因此结果是 0。
即是 该数字对 28 取模的结果被保存了下来。
1 | let uint8array = new Uint8Array(16); |
TypedArray 方法
TypedArray 具有常规的 Array 方法,但有个明显的例外。
我们可以遍历(iterate),map,slice,find 和 reduce 等。
但有几件事我们做不了:
- 没有
splice—— 我们无法“删除”一个值,因为类型化数组是缓冲区(buffer)上的视图,并且缓冲区(buffer)是固定的、连续的内存区域。我们所能做的就是分配一个零值。 - 无
concat方法。
还有两种其他方法:
arr.set(fromArr, [offset])从offset(默认为 0)开始,将fromArr中的所有元素复制到arr。arr.subarray([begin, end])创建一个从begin到end(不包括)相同类型的新视图。这类似于slice方法(同样也支持),但不复制任何内容 —— 只是创建一个新视图,以对给定片段的数据进行操作。
有了这些方法,我们可以复制、混合类型化数组,从现有数组创建新数组等。
DataView
DataView 是在 ArrayBuffer 上的一种特殊的超灵活“未类型化”视图。它允许以任何格式访问任何偏移量(offset)的数据。
- 对于类型化的数组,构造器决定了其格式。整个数组应该是统一的。第 i 个数字是
arr[i]。 - 通过
DataView,我们可以使用.getUint8(i)或.getUint16(i)之类的方法访问数据。我们在调用方法时选择格式,而不是在构造的时候。
1 | new DataView(buffer, [byteOffset], [byteLength]) |
buffer—— 底层的ArrayBuffer。与类型化数组不同,DataView不会自行创建缓冲区(buffer)。我们需要事先准备好。byteOffset—— 视图的起始字节位置(默认为 0)。byteLength—— 视图的字节长度(默认至buffer的末尾)。
ArrayBuffer 是核心对象,是对固定长度的连续内存区域的引用。
在大多数情况下,我们直接对类型化数组进行创建和操作,而将 ArrayBuffer 作为“共同之处(common denominator)”隐藏起来。我们可以通过 .buffer 来访问它,并在需要时创建另一个视图。
TextDecoder和TextEncoder
TextDecoder
二进制实际上是一个字符串该怎么表示呢?
内建的 TextDecoder 对象在给定缓冲区(buffer)和编码格式(encoding)的情况下,允许将值读取为实际的 JavaScript 字符串。
1 | let decoder = new TextDecoder([label],[options]) |
label—— 编码格式,默认为utf-8,但同时也支持big5,windows-1251等许多其他编码格式。options—— 可选对象:**fatal**ignoreBOM
解码
1 | let str = decoder.decode([input], [options]); |
input—— 要被解码的BufferSource。options—— 可选对象:**stream** —— 对于解码流
1 | let uint8Array = new Uint8Array([72, 101, 108, 108, 111]) |
TextEncoder
TextEncoder 做相反的事情 —— 将字符串转换为字节。
1 | let encoder = new TextEncoder(); |
只支持 utf-8 编码。
它有两种方法:
encode(str)—— 从字符串返回Uint8Array。encodeInto(str, destination)—— 将str编码到destination中,该目标必须为Uint8Array。
1 | let encoder = new TextEncoder(); |
Blob
在浏览器中,还有其他更高级的对象,特别是 Blob 在 File API中有描述
Blob 由一个可选字符串type(通常是MIME类型) 和 blobParts组成 一系列的Blob对象、字符串、BufferSource
 >
>
1 | new Blob(blobParts,options) |
- blobParts: 是
Blob/BufferSource/String类型的值的数组。 - options: type:
Blob类型endings是否转换换行符 默认为"transparent"(啥也不做),不过也可以是"native"(转换)。
例如
1 | let blob = new Blob(["<html>…</html>"], {type: 'text/html'}); |
我们可以用 slice 方法来提取 Blob 片段 (用法同 string.slice)
Blob对象是不可改变的 无法从Blob中更改数据但是可以通过slice获取新的blob 就类似于 字符串
Blob–URL
1 | let link = document.createElement('a'); |
浏览器内部为每个通过 URL.createObjectURL 生成的 URL 存储了一个 URL → Blob 映射。因此,此类 URL 很短,但可以访问 Blob 在内存中不会被消除 除非退出 该映射会被删除
Blob–base64
URL.createObjectURL 的一个替代方法是,将 Blob 转换为 base64-编码的字符串。
这种编码将二进制数据表示为一个由 0 到 64 的 ASCII 码组成的字符串,非常安全且“可读“。更重要的是 —— 我们可以在 “data-url” 中使用此编码。
1 | let link = document.createElement('a'); |
Image–blob
我们可以创建一个图像(image)的、图像的一部分、或者甚至创建一个页面截图的 Blob。这样方便将其上传至其他地方。
1 | // 获取任何图像 |
Blob–ArrayBuffer
1 | // 从 blob 获取 arrayBuffer |
Blob–Stream
当我们读取和写入超过 2 GB 的 blob 时,将其转换为 arrayBuffer 的使用对我们来说会更加占用内存。这种情况下,我们可以直接将 blob 转换为 stream 进行处理。stream 是一种特殊的对象,我们可以从它那里逐部分地读取(或写入)。
1 | // 从 blob 获取可读流(readableStream) |
File和FileReader
File
File对象继承自Blob 并扩展了与文件系统相关的功能
1 | new File(fileParts, fileName, [options]) |
fileParts—— Blob/BufferSource/String 类型值的数组。fileName—— 文件名字符串。options—— 可选对象:
从 <input type="file">或拖放或其他浏览器接口来获取文件。在这种情况下,file 将从操作系统(OS)获得 this 信息。
这就是我们从 <input type="file"> 中获取 File 对象的方式:
1 | <input type="file" onchange="showFile(this)"> |
输入(input)可以选择多个文件,因此
input.files是一个类数组对象。这里我们只有一个文件,所以我们只取input.files[0]。
FileReader
FileReader是一个对象 用处是从Blob对象中读取数据
1 | let reader = new FileReader(); // 没有参数 |
主要方法:
readAsArrayBuffer(blob)—— 将数据读取为二进制格式的ArrayBuffer。readAsText(blob, [encoding])—— 将数据读取为给定编码(默认为utf-8编码)的文本字符串。readAsDataURL(blob)—— 读取二进制数据,并将其编码为 base64 的 data url。abort()—— 取消操作。
读取过程中,有以下事件:
loadstart—— 开始加载。progress—— 在读取过程中出现。load—— 读取完成,没有 error。abort—— 调用了abort()。error—— 出现 error。loadend—— 读取完成,无论成功还是失败。
读取完成后,我们可以通过以下方式访问读取结果:
reader.result是结果(如果成功)reader.error是 error(如果失败)。
1 | <input type="file" onchange="readFile(this)"> |
V8垃圾回收机制和内存泄漏分析
V8
语言分类
解释执行
- 先将源代码通过解析器转化成中间代码,再用解释器执行中间代码,输出结果
- 启动快 执行慢
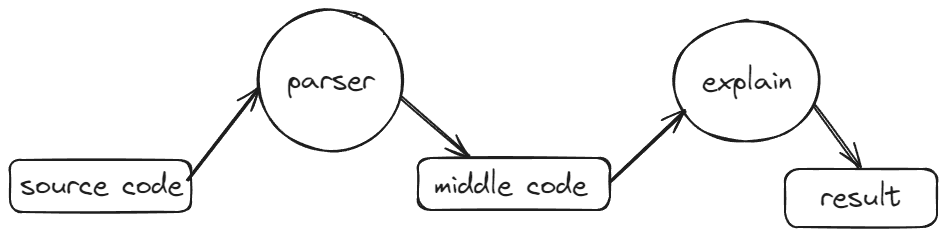
编译执行
- 先将源代码通过解析器转成中间代码 再用编译器把中间代码转成机器码 最后执行
- 启动慢 执行快
v8执行过程
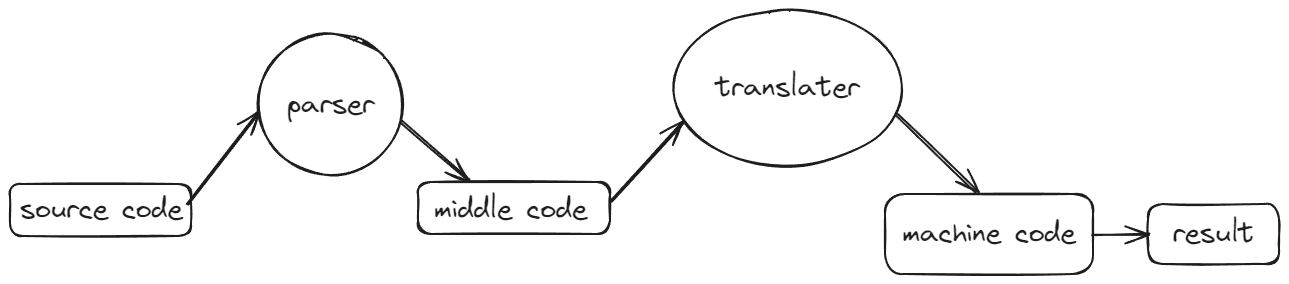
- V8采用的是解释和编译两种方式 这种混合方式称为JIT
- 第一步先由解析器生成抽象语法树和相关的作用域
- 第二步根据AST和作用域生成字节码 字节码是介于AST和机器码的中间代码
- 然后解析器直接执行字节码 也可以让编译器把字节码编译成机器码后在执行
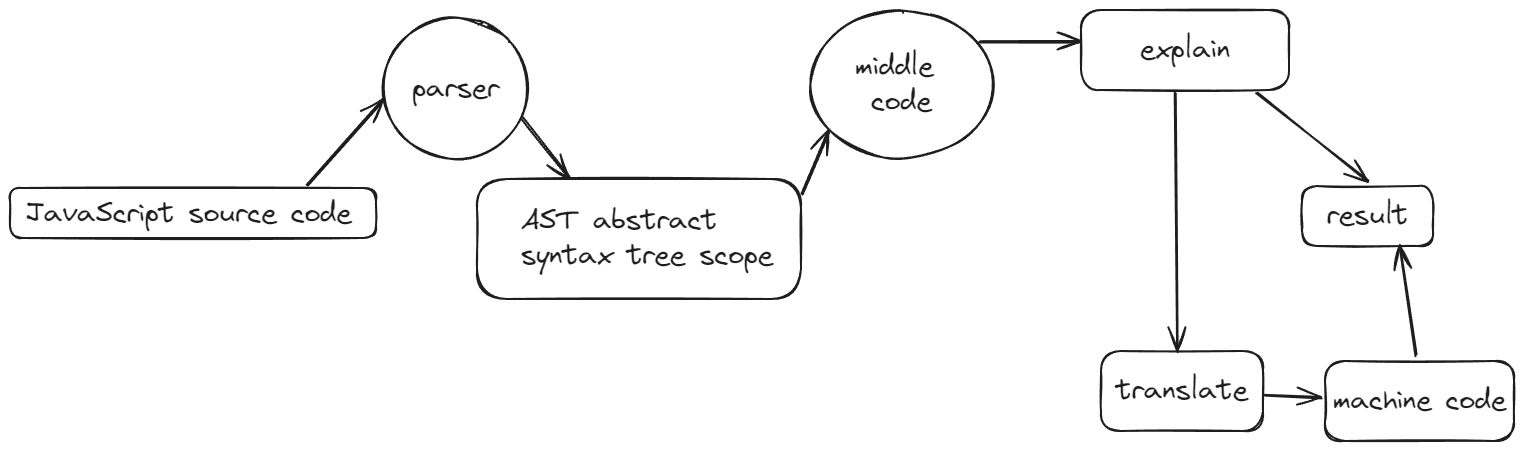
抽象语法树
astexplorer可以查看抽象语法树
1 | const a = 1 |
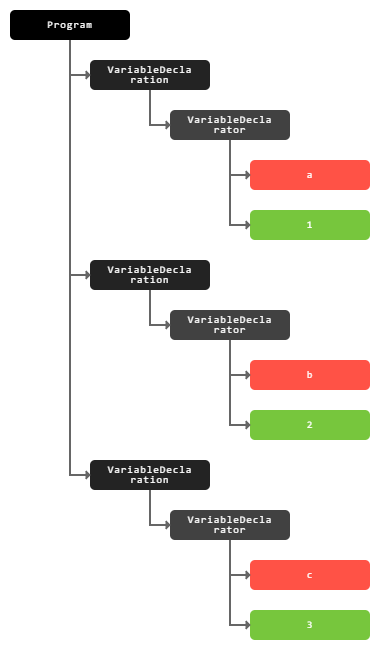
1 | { |
作用域
作用域是一个抽象的概念 描述了一个变量的生命周期
1 | Global scope |
字节码
- 字节码是机器码的抽象表示
- 源代码直接编译成机器码编译时间太长 体积太大 不适合
字节码就是机器码的抽象表示 类似与虚拟DOM 机器码等于不同宿主环境的具体实现 比如 node环境 DOM react-native 等
1 | [generated bytecode for function: assert (0x0295d247bb41 <SharedFunctionInfo assert>)] |
V8内存管理
- 程序运行需要内存分配
- V8也会申请内存 这种内存叫常驻内存集合
- 常驻内存集合又分成堆和栈
栈
- 栈用于存放JS中的基本类型和引用类型指针
- 栈的空间是连续的 增加删除只需要移动指针 操作速度非常快
- 栈的空间是有限的 当栈满了 就会抛出一个错误
- 栈一般都是执行函数时创建的 在函数执行完毕后 栈会被销毁
1 | function Person(name) { |
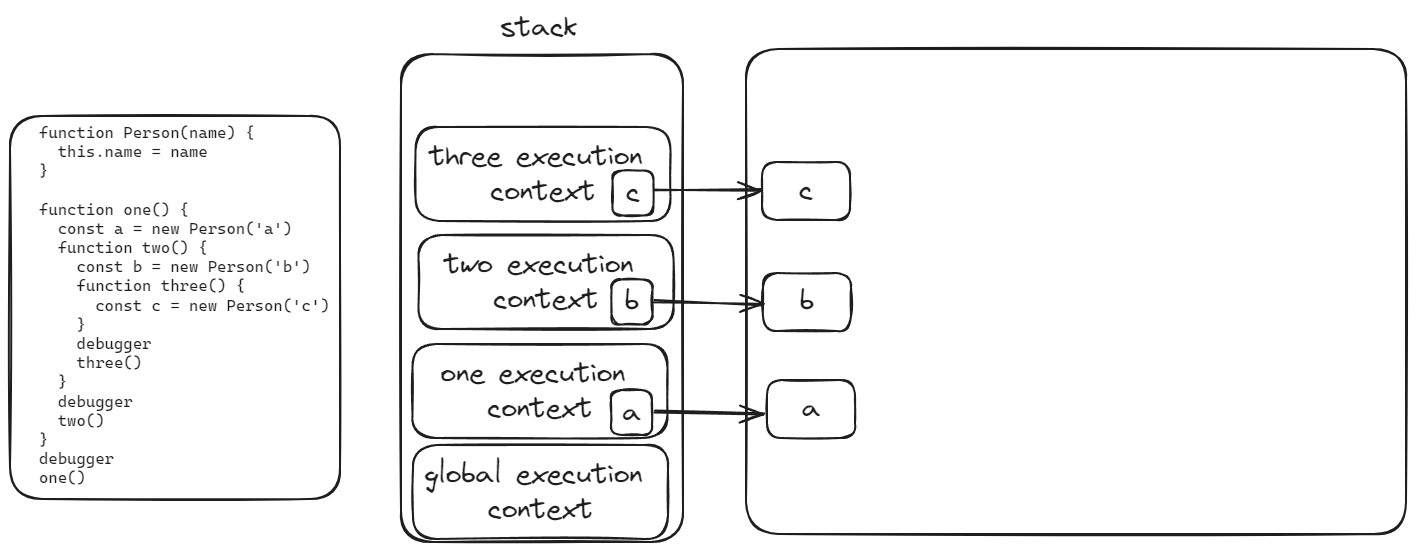
1 | function Person(name) { |
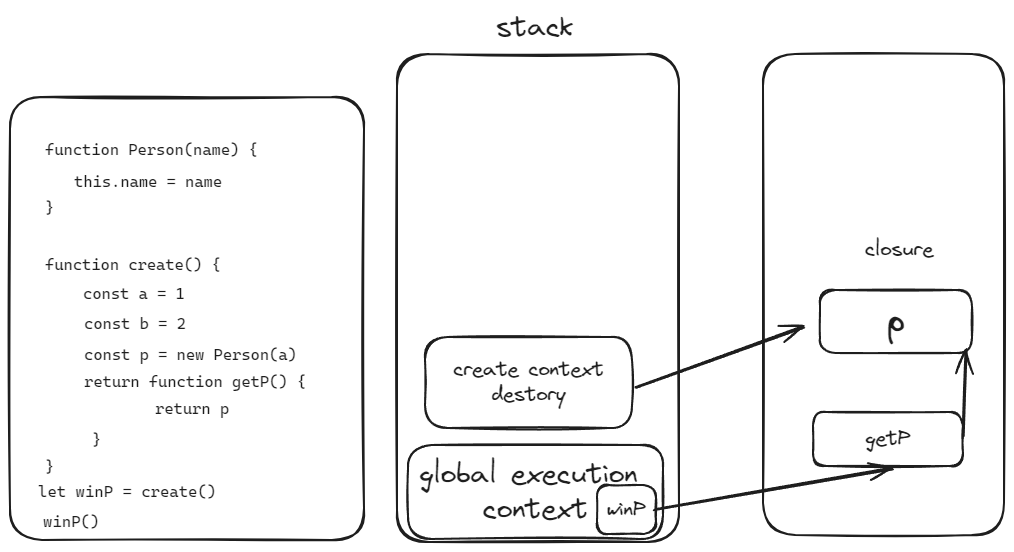
堆
- 如果不需要连续空间 或者申请的内存很大 可以使用堆
- 堆主要用于存储JS中的引用类型
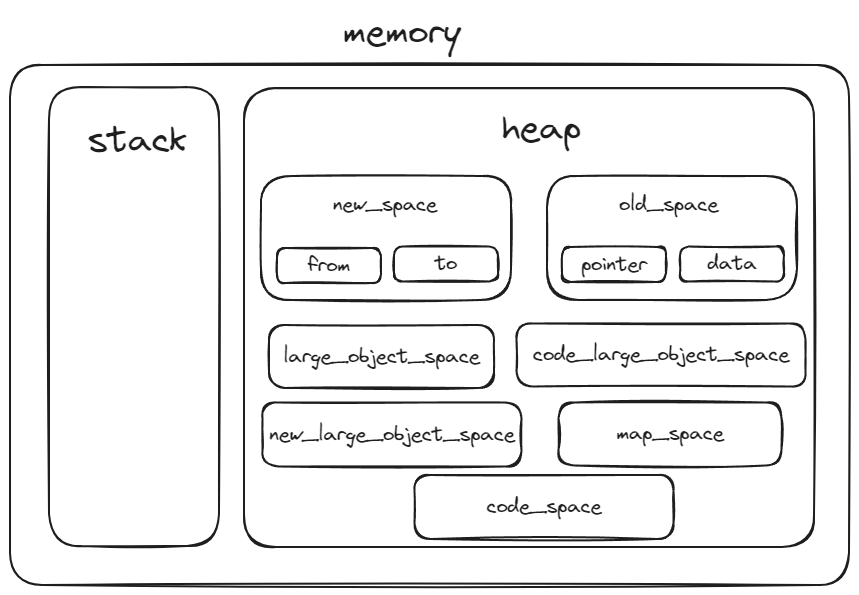
堆空间分类
新生代(new_space)
- 新生代内存用于存放一些生命周期比较短的对象数据
老生代 (old_space)
- 老生代内存用于存放一些生命周期比较长的对象数据
- 当
new space的对象进行两个周期的垃圾回收后 如果数据还存在new space中 则将他们存放到old_space中 - old space又可以分为两部分 分别是old pointer space和old data space
- old pointer space 存放GC后surviving的指针对象
- old data space 存放GC后surviving的数据对象
- old space 使用标记清除和标记整理的方式进行垃圾回收
运行时代码空间(code_space)
- 用于存放JIT已编译的代码
- 唯一拥有执行权限的内存
大对象空间(Large object space)
- 为了避免大对象的拷贝 使用该空间专门储存大对象
- GC不会回收这部分内存
隐藏类(Map Space)
- 存放对象的Map信息 即隐藏类
- 隐藏类是为了提升对象属性的访问速度的
- V8会为每个对象创建一个隐藏类 记录了对象的属性布局 包括所有的属性和偏移量
什么是垃圾
在程序运行过程中肯定会用到一些数据 这些数据会放在堆栈中 但是在程序运行结束后 这些数据就不会在被使用了 那么这些不再使用的就是垃圾
1
2
3
4global.a = {name: "a"}
global.a.b = {name: "b1"}
global.a.b = {name: "b2"}
// {name: b1} 不用了就是垃圾
新生代垃圾回收
- 新生代内存有两个区域 分别是对象区域(from) 和 空闲区域(to)
- 新生代内存使用
Scavenger算法来管理内存- 广度优先遍历From-Space中的对象 从root出发 广度优先遍历所有能到达的对象 把存活对象复制到To-Space中
- 遍历完成后清空From-Space
- From-Space和To-Space角色互换
- 复制后的对象在To-Spce中占用的内存空间是连续的 不会出现碎片问题
- 这种垃圾回收方式快速而又高效 但是会造成空间浪费
- 新生代的GC比较频繁
- 新生代的对象转移到老生代称为晋升Promote 情况有
- 经过一次GC还存活的对象
- 对象复制到To-Space时 To-Space 的空间达到一定限制
1 | global.a = {} |
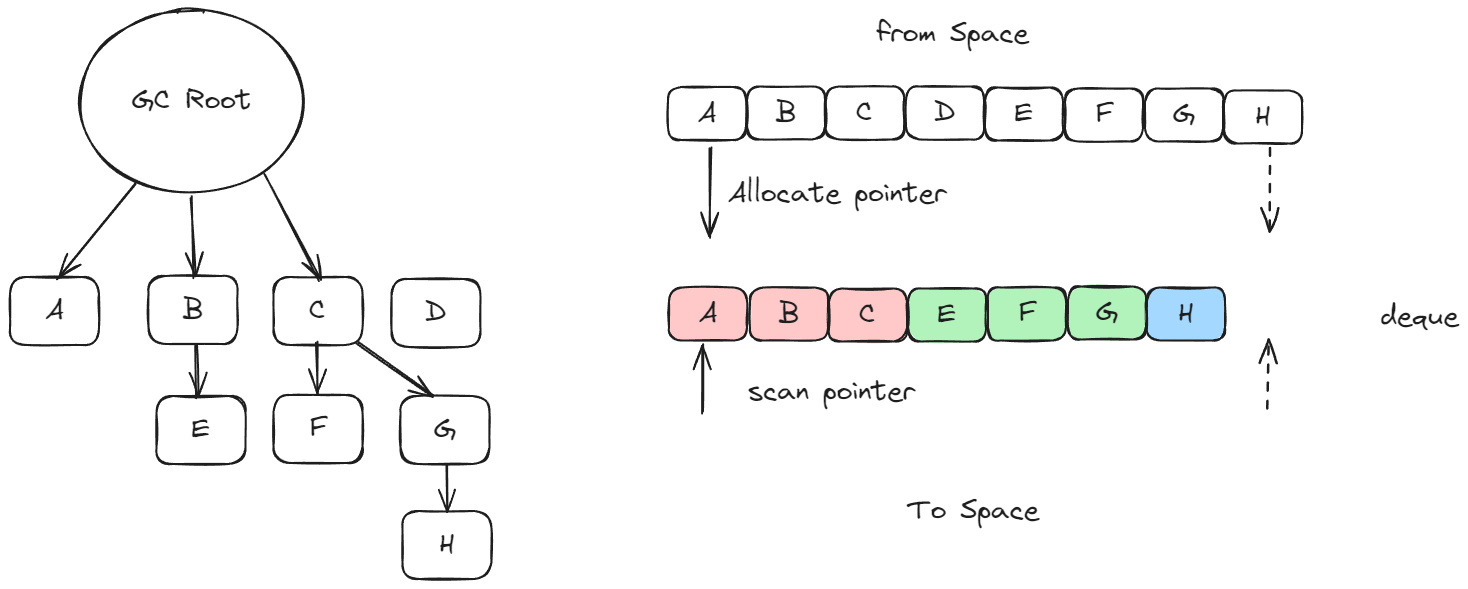
老生代的垃圾回收
- 老生代里的对象有些是从新生代晋升的 有些是比较大的对象直接分配到老生代里的 所以老生代的对象空间大 活得久
- 如果使用
Scavenge算法 浪费空间 而且复制大块的内存空间消耗时间会很长 显然不合适 - V8在老生代中垃圾回收策略采用Mark-Sweep(标记清除)和Mark-Compact(标记整合)相结合
Mark-Sweep(标记清除)
- 标记清除分为标记和清除两个阶段
- 在标记阶段需要遍历堆中的所有对象 并标记哪些活着的对象 然后进入清除阶段 在清除阶段 只清除没有被标记的对象
- V8采取的是黑色和白色来标记数据 垃圾收集之前 会把所有的数据设置成白色 用来标记所有的尚未标记的对象 然后会从GC ROOT出发以深度优先的方式把所有的能访问到的数据都标记为黑色 遍历结束黑的就是活数据 白的就是可以清理的垃圾数据
- 由于标记清除只清除死亡对象 而死亡对象在老生代中占用比例很小 所以效率很高
- 标记清除有一个问题就是进行一次标记清除后 内存往往不是连续的 会出现很多内存碎片 如果后续分配一个大的对象 所有的内存碎片都不够用会出现内存溢出问题
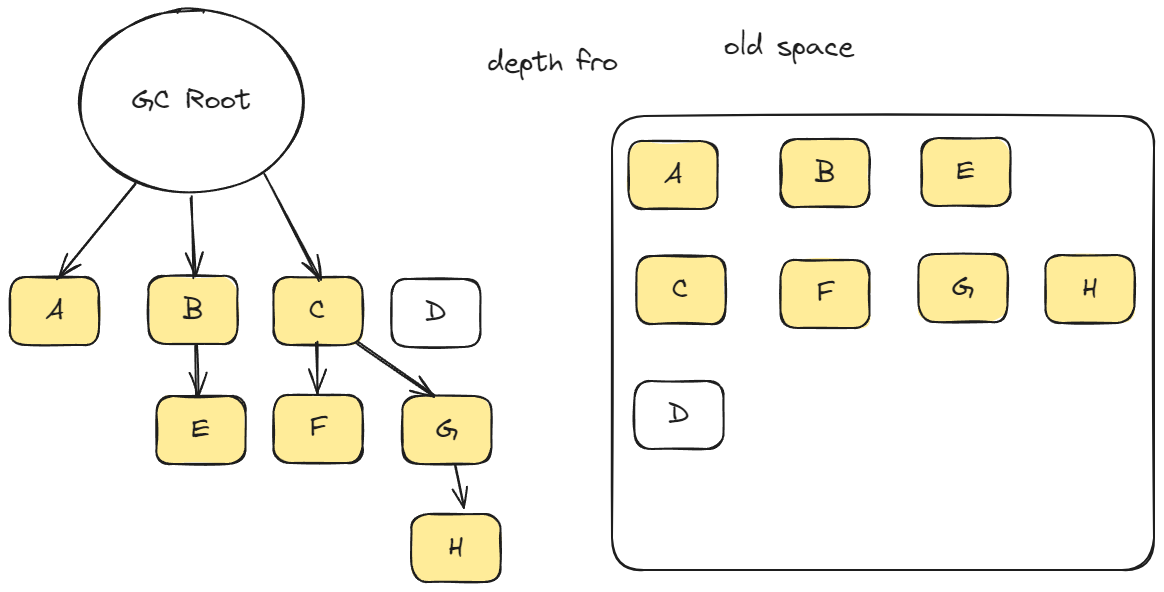
Mark-Compact(标记整理)
- 标记整理正是为了解决标记清除所带来的内存碎片问题
- 标记整理在标记清除的基础进行修改 将其的清除阶段变成紧缩极端
- 在整理的过程中 将活着的对象向内存区的一段移动 移动完成后直接清理掉边界外的内存
- 紧缩过程涉及对象的移动 所以效率并不好 但是能保证不会生成内存碎片 一般10次标记清理会伴随一次标记整理
优化
- 在执行垃圾回收算法期间 JS脚本需要暂停 这种叫Stop the world(全停顿)
- 如果回收时间过长 会引起卡顿
- 性能优化
- 如果把大任务拆分成小任务 分布执行 类似于fiber
- 将一些任务放在后台执行 不占用主线程
Parallel(并行执行)
- 新生代的垃圾回收采取并行策略提升垃圾回收速度 它会开启多个辅助线程来执行新生代的垃圾回收
- 并行执行需要的时间等于所有的辅助线程时间的总和加上管理的时间
- 并行执行的时候也是全停顿状态 主线程不能进行任何操作 只能等待辅助线程的完成
- 主要用于新生代的垃圾回收
增量标记
- 老生代因为对象又大又多 所以垃圾回收的时间更长 采用增量标记的方式进行优化
- 增量标记就是把标记工作分成多个阶段 每个阶段都只标记一部分对象 和主线程的执行穿插进行
- 为了支持增量标记 V8必须可以支持垃圾回收的暂停和恢复 所以采用了
黑白灰三色标记法- 黑色表示这个节点被GC ROOT 引用到了 而且该节点的子节点都已经标记完成了
- 灰色表示这个节点被GC ROOT引用到了 但子节点还没被垃圾回收器标记处理 表面正在处理这个节点
- 白色表示此节点还没未被垃圾回收器发现 如果在本轮遍历结束时还是白色 则这块数据将会很快被收回
- 引入了灰色标记后 就可以通过判断有没有灰色节点来判断标记是否完成了 如果有灰色节点下次回复应该从灰色开始执行
写屏障
- 当黑色指向白色节点的时候 就会触发写屏障 这个写屏障会把白色节点设置成灰色
Lazy Sweeping(惰性清理)
- 当标记完成后 如果内存够用 先不清理 等JS代码执行完慢慢清理
并发回收
- 其实增量标记和惰性清理并没有减少暂停的总时间
- 并发回收就是主线程在执行过程中 辅助线程可以在后台完成垃圾回收工作
- 标记操作全都由辅助线程完 清理操作由主线程和辅助线程配合完成
并发和并行
- 并发和并行都是同时执行任务
- 并行的
同时是同一时刻可以多个进程在运行 - 并发的
同时是经过上下文快速切换 使得看上去多个进程都在同时运行的现象
内存泄漏
内存泄漏:当不在用到的对象没有及时被回收时 即内存泄漏了
不合理的闭包
JS中的设计模式
设计模式介绍
- 设计模式是在解决问题的时候针对待定问题给出的简洁而优化的处理方案
- 在JS设计模式中 最核心的思想是: 封装变化
- 变与不变分离 变化的部分灵活 不变的部分稳定
构造器模式
复用对象
1 | function Employee(name, age, salary) { |
原型模型
1 | function Employee(name, age, salary) { |
ES6中使用类的写法 (结二唯一) 原型模式将函数挂在在原型对象上
1 | class Employee { |
工厂模式
由一个工厂对象决定创建某一种产品对象类实例 主要用来创建同一类对象
1 | function userFactory(role) { |
ES6写法
1 | class User { |
简单工厂的优点在于 只需要一个正确的参数 就可以获取到返回相应的对象 而无需知道创建的具体细节 简单工厂只能作于创建的对象数量较少 对象的创建逻辑不复杂的时候使用
抽象工厂模式
抽象工厂并不直接生成实例 而是生成对产品类的创建
1 | class User { |
建造者模式
建造者模式属于创建型模式的一种 提供一种创建复杂对象的方式 将一个复杂对象的构建与它的表示分离 使得同样的构建过程可以创建不同的表示
构建者是一步一步的创建一个复杂的对象 运行用户只通过指定复杂的对象类型和内容就可以构建
1 | class navbar { |
建造者模式将一个复杂对象的构建层与其表示层分离 同样的构建过程可采用不同的表示 工厂模式主要是为了创建对象实例或者类对象(抽象工厂) 关系的是最终的产出是什么 而不关心构建过程 建站者正好相反关注的是整个过程
单例模式
保证一个类只有一个实例 并提供一个访问它的全局访问点
主要解决一个全局使用的类频繁地创建和销毁 占用内存
1 | const single = (function () { |
1 | class Single { |
比如状态管理 vuex | Redux等 store 是单例模式
装饰器模式
转饰器模式能够对已有的功能进行拓展, 这样不会更改原有的代码, 对其他的业务产生影响 这方便我们在较少的改动下对软件功能进行拓展
比如现在给一个上传数据操作加上一个前置的PV操作
1 | Function.prototype.before = function (beforeFn) { |
适配器模式
将一个类的接口转换成客户端希望的另一个接口, 适配器模式让那些接口不兼容的类也可以一起工作
1 | class TencentMap { |
适配器不会去改变实现 主要作用是干涉了抽象的过程 外部接口的适配器能够让同一个方法适用于多个系统 比如经典的axios 分成web环境和node环境
策略模式
策略模式定义了一系列算法 并将每个算法封装起来 使它们可以相互替换 且算法的变化不会影响使用算法的客户 策略模式属于对象行为模式 通过对算法的封装 把算法的责任和算法的实现分开 并委派不同的对象对这些算法进行管理
主要解决了多种算法相似的时 使用 if else 带来的复杂和难以维护
1 | let stragery = { |
代理模式
代理模式(Proxy) 为其他对象提供一种代理以控制对这个对象的访问
代理模式使得代理对象控制具体对象的引用 代理几乎可以是任何对象 文件 资源 内存中的对象 或者一些难以复制的东西
1 | const stars = { |
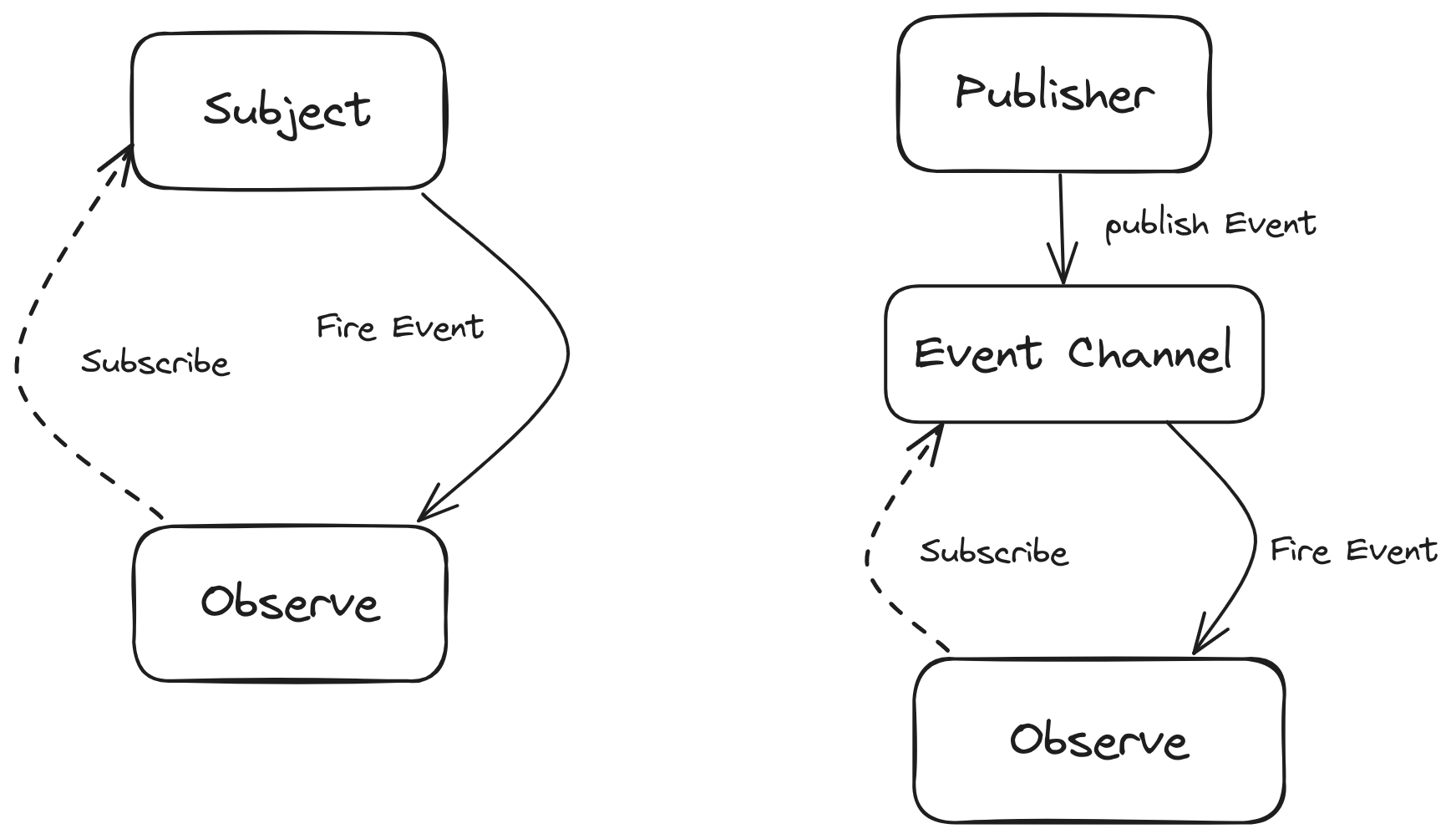
观察者模式
观察者模式包含观察目标和观察者两类对象
一个目标可以有任意数目的与之相依赖的观察者
一旦观察目标的状态发生改变 所有观察者将会得到通知
当一个对象的状态发生改变时、所有依赖于其它的对象都得到了通知 解决了主体对象与观察者之间的功能耦合 即一个对象状态改变给其他对象通知的问题
1 | // 观察目标 |
缺点: 观察者模式虽然实现了对象之间依赖关系的低耦合 但却不能对事件通知进行细分管控 如筛选通知、指定主题事件通知等
发布订阅模式
观察者和目标要相互知道
发布者和订阅者不用相互知道 通过第三方实现调度 属于经过解耦合的观察者模式